Actualidad informática
Noticias y novedades sobre informática
Vídeo musical interpretado por robots
En la página web de Nigel Stanford hay algunos vídeos más sobre cómo hizo las pruebas y ajustes para que todo esto sonara bien: Automatica Robot Tests. Utiliza brazos robóticos industriales, de los de cientos de kilogramos de masa.
![]()
Un proyecto europeo aborda los retos de la informática a gran escala
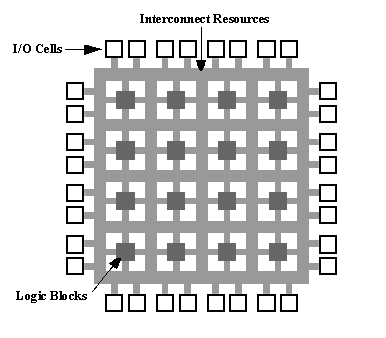
Un proyecto paneuropeo ha comenzado este mes para reunir las tecnologías necesarias para la computación a gran escala, abordando el reto clave del uso de la energía.
El proyecto EuroEXA, de 20 millones de euros, ha comenzado este mes reuniendo tres proyectos a gran escala sobre aceleradores FPGA, interconexiones y tecnologías de chip 3D para alcanzar un rendimiento de 1018 operaciones, 10 veces superior al de los superordenadores más rápidos de la actualidad.
El factor limitante para la computación a gran escala es la eficiencia energética, dice el Dr. Dirk Koch de la Universidad de Manchester, que forma parte del proyecto Ecoscale. Señala al superordenador chino Sunway Taihulight como no muy lejos de la exascala, con 10000 núcleos que utilizan 28 MW de potencia para 125 petaflops de rendimiento. Si se considera la exascala, necesitamos 8 veces ese rendimiento, pero esto es más que todo el rendimiento de los 500 mejores superordenadores «, dijo. «Serían más de 85000 núcleos que necesitarían 224 MW de potencia. Son 40000 dólares por hora o 340 millones de dólares al año en EE. UU., y costaría más de 2000 millones de dólares «.
Así que la eficiencia energética es la clave última, y la integración es la clave para el rendimiento, cuanto más se puede hacer en un solo chip mejor «, dijo. Señala que el rendimiento de un FPGA es el doble del de una GPU en un problema específico para una décima parte de la potencia. «Es exactamente a donde queremos ir», dijo. «Eso usaría 40 MW a exascala. Esta es la belleza de los FPGA, que integran más funciones en un solo chip. La gestión de datos es clave. No se mueven los datos para computar, sino que se mueven la computación a los datos, lo que significa reconfigurar la FPGA donde están los datos «.
El mero uso de CPUS y GPU no hará el trabajo y tiene que hacerse con FPGA que necesitarán nuevos modelos de programación. En Manchester estamos trabajando en OpenCL como modelo de programación para módulos configurables que se pueden conectar a un sistema como acelerador HPC «.
Los otros dos proyectos se centran en la interconexión informática de alto rendimiento y el empaquetado de chips en 3D para lograr interconexiones locales más rápidas.
Ampliar en: eeNews
![]()
Ford desarrolla la comunicación entre el coche automático y los humanos
![]()
Junto con el Instituto Tecnológico de Transporte de Virginia, Ford Motor Company está probando un sistema que permite a los vehículos autónomos y a los conductores humanos comunicarse entre sí. Ford utiliza un coche que parece conducir de forma autónoma.
En el tráfico cotidiano, los usuarios de la vía pública se comunican intuitivamente a través de pequeños gestos: un guiño es a menudo suficiente para indicar que la otra persona puede pasar. Este elemento de comunicación falta en los automóviles autónomos. Ford está probando ahora cómo podría ser un «lenguaje de gestos» simple, entre los usuarios de vehículos robóticos y los humanos.
Cuando Daimler envió un Mercedes autónomo a través del tráfico en 2013, una debilidad fundamental de los chóferes electrónicos se hizo evidente: una pareja de ancianos esperaba en un paso de peatones. El Mercedes automático parado permitía al peatón cruzar. Sin embargo, los dos peatones hicieron un gesto para dejar claro que preferirían que el coche fuera el primero en pasar. La computadora a bordo del Mercedes no entendió la pista e insistió en no continuar hasta después de los peatones. La situación de bloqueo sólo podría resolverse tras la intervención del conductor de control humano.
Este problema sigue esperando una solución. Dondequiera que en el mundo los coches autónomos participan en el tráfico normal, estos malentendidos ocurren. Ahora Ford está trabajando con el Instituto Tecnológico de Transporte de Virginia Tech para establecer una interacción entre los humanos y los usuarios electrónicos de la carretera, proporcionando señales fáciles de entender. «Entender cómo los vehículos autopropulsados pueden operar en el mundo real es la base para el desarrollo de la futura realidad del tráfico», dice John Shutko, Especialista Técnico en Factores Humanos de Ford Motor Company. «Debemos encontrar soluciones al reto de garantizar que en algún momento ningún conductor humano esté al volante. Se trata de cómo sustituir los gestos humanos naturales para garantizar el funcionamiento seguro y eficiente de los vehículos autopropulsados en los espacios públicos».
Inicialmente, los investigadores consideraron la posibilidad de mostrar información textual grande sobre el vehículo, pero esto requeriría que todos los usuarios de la carretera entendieran el mismo idioma. El uso de símbolos fue rechazado porque los nuevos símbolos no son suficientemente reconocidos por los humanos. Al final, experimentaron con señales de luz. Las señales luminosas para el giro y la indicación de los frenos son ya de serie y generalmente aceptadas, por lo que una aplicación lumínica se considera el medio de comunicación más eficaz.
Por ejemplo, un vehículo autopropulsado puede indicar si funciona en modo de conducción autónomo, si desea arrancar o si quiere permanecer parado. Hacia este extremo, Ford colocó una barra de luz en el parabrisas de un vehículo de prueba. Además, se instalaron seis cámaras HD para detectar el comportamiento de otros usuarios de la carretera en una vista panorámica de 360 grados.
Para simular la conducción autónoma sin una persona al volante, los investigadores desarrollaron un traje de camuflaje que oculta a la persona en el asiento del conductor. El traje se parece al asiento de un conductor normal desde el exterior y crea la ilusión de un vehículo autónomo. Esto es esencial para la evaluación de los encuentros reales entre el transportista y otros usuarios de la carretera.
El equipo ha experimentado con tres escenarios de iluminación diferentes para probar los efectos de las siguientes señales del vehículo:
Modo de conducción autónomo: La barra de luces se ilumina constantemente en blanco para indicar que el vehículo se encuentra en modo de conducción autónomo:
Inicio: Luz blanca que parpadea rápidamente para mostrar la aceleración inminente desde un inicio en reposo.
Parada: Dos luces blancas que se mueven lateralmente indican que el vehículo está parando.
La simulación se llevó a cabo con el vehículo de prueba Ford Transit Connect en las carreteras públicas del norte del estado norteamericano de Virginia, donde hay una alta densidad de tráfico y relativamente muchos peatones. A lo largo de una distancia de unos 2500 kilómetros, los investigadores grabaron vídeos y protocolos de las reacciones a los encuentros con peatones, ciclistas y otros vehículos. Se realizaron experimentos en el tráfico urbano, incluso en intersecciones y aparcamientos. Los investigadores utilizarán los datos obtenidos para comprender cómo reaccionan los usuarios de la carretera a las señales de un vehículo autopropulsado.
El fabricante también está trabajando con varias organizaciones de normalización, incluyendo la Organización Internacional de Normalización y SAE, para promover la creación de un estándar industrial. Una interfaz de comunicación visual común que la mayoría de las personas puedan comprender universalmente sería importante para garantizar la integración segura de los vehículos autónomos en los sistemas de transporte existentes.
Ampliar en: eeNews
![]()
Facebook multado con 1.2 millones de euros por la Agencia Española de Protección de Datos

La Agencia de Protección de datos informó que ha impuesto a Facebook una multa de 1.2 millones de euros (1.44 millones de dólares) por no impedir que los anunciantes accedan a los datos de sus usuarios.
Facebook ha recabado datos personales de sus usuarios en España sin obtener su «consentimiento inequívoco» y sin informarles de la forma en que se va a utilizar, según ha manifestado la Agencia Española de Protección de Datos en un comunicado.
«Facebook recopila datos sobre ideología, sexo, creencias religiosas, gustos personales o navegación sin informar claramente sobre el uso y propósito que les dará», dice la declaración. El organismo de control dijo que la política de privacidad de Facebook «contiene términos genéricos y confusos» y «no recoge adecuadamente el consentimiento de sus usuarios o no usuarios, lo que constituye una infracción grave» de las normas de protección de datos.
La agencia dijo que Facebook no ha eliminado los datos personales que recopila de su base de datos, incluso cuando un usuario lo solicita. Afirmó que multó a la empresa con 600000 euros por una violación muy grave de las normas de protección de datos del país y con 300000 euros cada una por dos violaciones graves.
La multa de 1.2 millones de euros es pequeña en el contexto de la empresa, que obtuvo unos ingresos publicitarios de 9200 millones de dólares en el segundo trimestre, principalmente por la venta de publicidad en vídeo móvil.
Es el último de una serie de problemas legales que han acosado al gigante de las redes sociales en los últimos años. La agencia de protección de datos francesa impuso en mayo una multa de 150000 euros a Facebook por no haber evitado que los anunciantes accedieran a los datos de sus usuarios tras una investigación de dos años. Decía entonces que Facebook había creado «una recopilación masiva de datos personales de usuarios de Internet para mostrar publicidad dirigida». El año pasado, el organismo de control francés concedió a Facebook un plazo límite para dejar de seguir la actividad web de los no usuarios sin su consentimiento y ordenó a la red social que dejara de transferir algunos datos personales a los Estados Unidos.
Los gobiernos de Bélgica, Alemania y Holanda también están estudiando cómo Facebook mantiene y utiliza los datos de sus ciudadanos, según la agencia española de protección de datos.
A nivel europeo se ha formado un «grupo de contacto» para proteger los datos personales de los usuarios de Facebook, compuesto por la Agencia Española de Protección de Datos y sus homólogos de Francia, Bélgica, Alemania y Holanda.
La red social de Facebook, que ahora cuenta con 2010 millones de usuarios activos mensuales, está impulsando constantemente las ventas a un ritmo más rápido que otros gigantes de la tecnología.
![]()
El lenguaje Smalltalk podría ser el Nikola Tesla de la industria de TI

Sus contribuciones al mundo fueron enormes, pero la gente todavía recuerda a Edison y Franklin y da Vinci y Bell. Durante décadas, los intentos de honrar a Tesla con un museo de Nueva York (EE.UU.) en Wardenclyffe fracasaron repetidamente. Solo recientemente han dado sus frutos
Aquí están algunas de las contribuciones de Tesla:
– inventó el primer motor de corriente alterna (AC)
– desarrolló la generación de CA y tecnología de transmisión
– creó la bobina Tesla, un transformador de alto voltaje que llegó a ser la génesis del tubo de rayos catódicos, radiotransmisor, radar y muchas otras tecnologías
– inventó la tecnología de rayos X
– inventó los dínamos y el motor de inducción
– inventó la primera radio operativa
– inventó la bombilla de luz fluorescente
– inventó el mando a distancia
– inventó la transmisión inalámbrica de electricidad
– diseñó la primera central hidroeléctrica de las Cataratas del Niágara
En 1887 y 1888, se le concedieron más de 30 patentes por sus invenciones.
Cuando Tesla faclleció en 1943, murió sin dinero y olvidado.
Smalltalk fue la creación de Alan Kay, un verdadero visionario que lideró un equipo brillante en Xerox PARC
Hoy en día, Smalltalk está muy subestimado. Aunque Kay nunca pensó que Smalltalk fuera el foco central de su visión, sigue siendo una poderosa fuerza para el avance de la tecnología de programación. Más de cuatro décadas después, ningún lenguaje de programación ha alcanzado a Smalltalk en términos de simplicidad y elegancia, mínima fricción cognitiva, pureza orientada a objetos, elegante codificación y depuración en vivo, enorme productividad de programador y respeto profesional.
En Slant and StackOverflow, Smalltalk es reverenciado: lee La Sabiduría de la muchedumbre.
Capers Jones de Namcook Analytics ha demostrado la tremenda ventaja de Smalltalk cuando se trata de la productividad de los programadores.
El IDE de codificación en vivo de Smalltalk y el runtime son increíblemente potentes sin la complejidad arcana que se encuentra en los IDEs modernos como Visual Studio, Eclipse y Xcode.
Smalltalk continúa evolucionando y mejorando de manera notable a través del proyecto Pharo. He aquí algunas grandes innovaciones:
– NativeBoost – tener un ensamblador en línea definitivamente no es una característica común en un lenguaje dinámico. NativeBoost ha evolucionado desde entonces a la Interfaz Unificada de Función Extranjera (o UFFI).
– Moose es un conjunto de herramientas de visualización de códigos que contiene muchos medios para visualizar y analizar el código.
– Amber, que utiliza Pharo como lenguaje de referencia, es una fantástica herramienta de programación web de primera línea.
– PharoJS es otra herramienta de programación web excelente.
– Continuations: son una característica maravillosa en el marco web de Seaside.
– Fuel: una forma de serializar objetos vivos y de transportar sus objetos.
– Oz – permite que una imagen manipule otra. Muy bueno para depurar una imagen que se ha bloqueado y no puede abrir/cargar.
– Pharo Launcher te permite gestionar tus imágenes Pharo (lanzar, renombrar, copiar y eliminar) y descargar plantillas de imágenes (es decir, archivos zip) de muchas fuentes diferentes para crear nuevas imágenes a partir de cualquier plantilla.
– SmalltalkHub es el Github de Pharo, pero a diferencia de Github es totalmente open source y todo Smalltalk.
– Phratch es un puerto de Scratch a Pharo – esto es importante porque Scratch ha sido transferido a HTML5 y esto es un esfuerzo para mantener basado en Scratch Smalltalk. Phratch es una plataforma excelente para enseñar a los niños a codificar.
– Shampoo – buen soporte para Pharo en Emacs; puedes reemplazar la GUI Pharo con Emacs y disfrutar de los beneficios de este poderoso editor.
Legado
Como Tesla, Smalltalk tiene un legado maravilloso. Su bella implementación de programación orientada a objetos ha influido directamente en el diseño de casi todos los lenguajes orientados a objetos que usamos hoy en día: Java, Python, C#, PHP, Ruby, Perl, Objective-C, Groovy, Scala, Dart, Erlang, CLOS.
Smalltalk introdujo al mundo a la máquina virtual de lenguajes. (No, no fue el primero, pero fue el más conocido.) Esta es la misma tecnología que soporta Java y. NET.
Smalltalk fue pionera en la recopilación JIT (just-in-time).
De Smalltalk surgió el primer IDE moderno (entorno de desarrollo integrado), que incluía un editor de texto, un navegador de sistemas o clases, un inspector de objetos o propiedades y un depurador.
Smalltalk fue la primera herramienta de lenguaje que soportó programación en vivo y técnicas avanzadas de depuración tales como inspección sobre la marcha y cambios de código durante la ejecución en una forma fácilmente utilizable.
Desde que Smalltalk-80 (en 1980), tenía funciones y clausuras de primera clase que, curiosamente, hacen que Smalltalk sea bastante bueno para la programación funcional. Bastante notable para un lenguaje «puro» orientado a objetos. (¿Cuánto tiempo tardó Java, Python, C# y C++ en obtener esta función?
Smalltalk introdujo el patrón arquitectónico de software MVC (Model-View-Controller).
En gran medida, Smalltalk es responsable de proporcionarnos un desarrollo basado en pruebas (o TDD) y una programación extrema (o XP), que son ambos muy influyentes en las prácticas ágiles estándar de hoy en día.
Smalltalk hizo de «teclear el pato» una palabra familiar. La escritura de tipo de pato es donde la «comprobación de tipo» se aplaza hasta el tiempo de ejecución – cuando se utilizan las capacidades de reflexión para asegurar un comportamiento correcto. Hoy en día, encontramos el mecanografiado de patos en muchos idiomas, incluyendo Java, Python, Go, Groovy, Objective-C y PHP.
Smalltalk ha sido pionera en el desarrollo de bases de datos de objetos de las que GemStone/S es un gran ejemplo.
Smalltalk nos dio el primer navegador de refactoring.
Smalltalk fue fundamental en el desarrollo de la interfaz gráfica de usuario (o GUI) y la interfaz de usuario «lo que ves es lo que obtienes» (WYSIWYG).
La gente no se da cuenta de esto, pero Smalltalk es tan extensible como Lisp! Lee Lisp, Smalltalk, y el Poder de la Simetría. ¿Quién necesita las macros Lisp?
El éxito de Apple debe mucho a Smalltalk. Es verdad!
El objetivo C ha sido la base de macOS e iOS, y el objetivo C es esencialmente un cruce entre C y Smalltalk.
MacOS evolucionó a partir de NeXTStep, que se construyó con el Objetivo-C.
Steve Jobs se inspiró en la GUI y WIMP de Xerox PARC para realinear completamente la estrategia de Apple; la GUI fue una salida directa del trabajo de Smalltalk.
¡Uf! ¡Nikola Tesla habría estado orgullosa!
Ampliar en: Hackernoon
![]()
¿Google está a punto de construir el primer qubit del mundo?

El qubit es la unidad básica de computación cuántica. Así que a los desarrolladores de hardware cuántico obviamente les gusta presumir de cuántos tienen. Aunque algunos afirman tener miles en sus dispositivos, hay un sentimiento muy real de que nadie ha construido ni siquiera uno solo.
Hay un par de cosas diferentes para las que usamos el nombre del qubit. Uno es un qubit físico. La parte física se refiere al hecho de que estos son objetos reales de la vida real. La parte de bits nos dice que estos objetos deberían tener dos posibles estados. Y lo que es para el cuántico, ya que necesitamos manipular los estados de una manera cuántica mecánica.
Cualquier qubit que merezca el nombre también debe tener un ruido extremadamente bajo. La forma en que los manipulamos e interactuamos debería ser casi perfecta. Como un logro de la física experimental, deben estar en la cúspide: Una maravilla de la ciencia y la ingeniería. Aun así, no son suficientemente buenos. Para las ordenadores cuánticos, casi perfecto es casi inútil.
Esto no es más de lo que esperamos de los ordenadores normales. Hay millones de píxeles en tu pantalla, pero te darías cuenta si sólo uno estuviera haciendo algo al azar. Lo mismo es cierto para todos los millones de bits que nadan alrededor en sus programas. Sólo se necesita un valor de conmutación de unos pocos porque están aburridos para que todo se convierta en un sinsentido.
Cuando programamos, a menudo olvidamos que los bits de nuestro ordenador tienen una forma corpórea real. Pensamos en ellos como un concepto abstracto, puro e incorruptible. De lo contrario, el desarrollo de software sería una actividad muy diferente. Los programas cuánticos están diseñados con el mismo grado de perfección en mente. Para ejecutarlos, necesitamos renuncias lógicas: encarnaciones de la idea misma de la información cuántica.
Construir qubits lógicos requiere que domemos la naturaleza de sus primos físicos. Necesitamos corrección de errores cuánticos. Muchas de las partes físicas son reunidas y conducidas a ser más grandes que la suma de sus partes. Cuanto más qubits físicos usemos, mejor será el efecto. El ruido disminuye exponencialmente, hasta que podemos estar seguros de que no ocurrirá ni un solo error durante el cálculo.
Esto no está exento de costes. No debemos pensar en gastar unos pocos cientos de qubits físicos para construir uno solo lógico. Pero si esto significa alcanzar la promesa completa de computación cuántica, valdrá la pena.
El diseño más popular para la corrección de errores cuánticos es el código de superficie. Para el código de superficie más pequeño, se necesitan 17 qubits físicos. Éstos construirían un qubit lógico, pero no con la suficiente complejidad como para hacer algo con él.
Todavía no se ha logrado nada parecido. Para ver por qué, echemos un vistazo a lo que se necesitaría.
Esto es un código de superficie. Los 17 puntos, tanto blancos como negros, son los qubits físicos. Las 24 líneas coloreadas representan un cierto tipo de operación cuántica, la controlada-NO. Para cada par de salidas conectadas, esta operación debería ser posible realizarla de forma limpia y directa.
El principal desafío es conectar todos estos controles-NO. Tener 17 qubits en nuestro procesador cuántico no es suficiente. También necesitamos el conjunto de instrucciones para soportar esta red específica de procesos.
Tener un montón de qubits físicos en una línea son noticias viejas, dos líneas al lado de la otra también es factible. Pero la red 2D de conexiones necesarias para el código de superficie es mucho más difícil.
Aun así, Google promete esto y mucho más para finales de año. Prometieron una red de 7×7 de 49 qubits físicos. Esto sería un gran paso adelante en comparación con otros dispositivos, como la celosía IBM 2×8 de 16 qubits físicos.
El dispositivo IBM tiene suficiente conectividad para hacer un bit lógico a partir de qubits físicos. En los próximos meses harán cosas mucho más geniales, como es de esperar del dispositivo a la vanguardia de su campo. Pero hacer un qubit lógico no será uno de sus logros.
El hecho de que los 49 qubits de Google serán tan revolucionarios hace difícil creer que lo veremos antes de que acabe el año. Los hitos más realistas para este año son un dispositivo de 17 qubit de IBM, y uno de 20 qubit de Google. Ambos tienen suficientes qubits para empezar con el código de superficie. Pero, ¿tienen el diseño correcto? Sólo el tiempo lo dirá.
Quizá no tengamos que esperar mucho tiempo. John Martinis, el encargado de construir los dispositivos cuánticos de Google, dará una charla la próxima semana. El título…
Escalado de errores lógicos de medición con el código de superficie
Los códigos de superficie están en el radar de los gigantes tecnológicos. El primer qubit lógico del mundo se acerca. ¿Ya lo ha gestionado el dispositivo de 20 qubit de Google?
Ampliar en: HACKERMOON
![]()
Frigorífico que se desplaza respondiendo a las llamadas de voz

El frigorífico de Panasonic cuenta con una app para smartphone que le permite recibir las órdenes del usuario, tales como “ven al salón” para que acerque tu vaso de agua, por ejemplo, y no te pierdas ni un segundo de ver una película, o “ven a mi habitación” para que te lleve el desayuno sin que tengas que levantarte.
En IFA demostraron su funcionamiento, el cual se basa en radares LIDAR para detectar y evitar los obstáculos en su camino.
![]()
IBM está modelando nueva IA a partir del cerebro humano

Robots Atentos
Actualmente, las tecnologías de inteligencia artificial (IA) son capaces de exhibir rasgos aparentemente humanos. Algunos son intencionalmente humanoides, y otros realizan tareas que normalmente asociamos estrictamente con la humanidad – la composición de canciones, la enseñanza y el arte visual.
Pero a medida que el campo avanza, las empresas y los desarrolladores están replanteándose la base de la inteligencia artificial examinando nuestra propia inteligencia y cómo podríamos imitarla eficazmente utilizando maquinaria y software. IBM es una de estas compañías, ya que se han embarcado en la ambiciosa búsqueda de enseñar a AI a actuar más como el cerebro humano.
Muchos de los sistemas de aprendizaje de máquinas existentes se construyen en torno a la necesidad de extraer datos de conjuntos de datos. Ya sea que estén resolviendo problemas para ganar un juego de Go o identificando el cáncer de piel a partir de imágenes, esto a menudo sigue siendo cierto. Sin embargo, esta base es limitada y se diferencia del cerebro humano.
Nosotros, como humanos, aprendemos progresivamente. En pocas palabras, aprendemos sobre la marcha. Mientras que adquirimos el conocimiento para extraer a medida que avanzamos, nuestros cerebros se adaptan y absorben la información de manera diferente a como se construyen muchos sistemas artificiales existentes. Además, somos lógicos. Usamos las habilidades de razonamiento y la lógica para resolver problemas, algo que estos sistemas todavía no son fabulosos para lograr.
IBM está buscando cambiar esto. Un equipo de investigación en DeepMind ha creado una red neuronal sintética que supuestamente usa razonamiento racional para completar tareas.
Maquinaria Racional
Al dar a la IA múltiples objetos y una tarea específica,»estamos obligando explícitamente a la red a descubrir las relaciones que existen», dice Timothy Lillicrap, un informático de DeepMind en una entrevista con Science Magazine. En una prueba de la red realizada en junio pasado, se cuestionó sobre una imagen con múltiples objetos. A la red se le preguntó, por ejemplo:»Hay un objeto delante de la cosa azul; ¿tiene la misma forma que la pequeña cosa cian que está a la derecha de la bola de metal gris?»
En esta prueba, la red identificó correctamente el objeto un asombroso 96 por ciento de las veces, en comparación con el insignificante 42 a 77 por ciento que los modelos de aprendizaje de máquinas más tradicionales lograron. La red avanzada era también apta para los problemas de palabra y continúa siendo desarrollada y mejorada. Además de las habilidades de razonamiento, los investigadores están avanzando en la capacidad de la red para prestar atención e incluso crear y almacenar recuerdos.
El futuro del desarrollo de la IA podría acelerarse y expandirse enormemente mediante el uso de este tipo de tácticas, según Irina Rish, miembro del personal de investigación de IBM, en una entrevista con Engadget,»El aprendizaje en redes neuronales es típicamente diseñado y cuesta mucho trabajo crear una arquitectura específica que funcione mejor. Es más o menos un enfoque de ensayo y error… Sería bueno que esas redes se construyeran solas.»
Puede ser atemorizante pensar en la construcción y mejora de las redes de inteligencia artificial, pero si se monitorean, inician y controlan correctamente, esto podría permitir que el campo se expanda más allá de las limitaciones actuales. A pesar de los temores de una toma de control robótica, el avance de las tecnologías de IA podría salvar vidas en el campo médico, permitir a los humanos llegar a Marte, y mucho más.
Ampliar en: futurism
![]()
Flip-flop qubits: Nuevo diseño de computación cuántica radicalmente nuevo

Ingenieros de la Universidad de Nueva Gales del Sur (Australia) han inventado una nueva arquitectura para la computación cuántica, basada en novedosos «qubits de flip-flop», que promete hacer que la fabricación a gran escala de chips cuánticos sea mucho más barata -y más fácil- de lo que se pensaba.
El nuevo diseño del chip, detallado en la revista Nature Communications, permite un procesador cuántico de silicio que puede ampliarse sin necesidad de colocar los átomos con precisión en otros enfoques. Es importante destacar que permite que los bits cuánticos (o «qubits») -la unidad básica de información en un ordenador cuántico- se coloquen a cientos de nanómetros de distancia y permanezcan acoplados.
El diseño fue concebido por un equipo liderado por Andrea Morello, Gerente de Programa en el Centro de Excelencia ARC para Computación Cuántica y Tecnología de la Comunicación (CQC2T) con sede en Sydney, UNSW, quien dijo que la fabricación del nuevo diseño debe estar fácilmente al alcance de la tecnología actual.
El autor principal Guilherme Tosi, investigador asociado del CQC2T, desarrolló el concepto pionero junto con Morello y los coautores Fahd Mohiyaddin, Vivien Schmitt y Stefanie Tenberg del CQC2T, junto con los colaboradores Rajib Rahman y Gerhard Klimeck de la Universidad Purdue en los Estados Unidos.
«Es un diseño brillante, y como muchos saltos conceptuales, es increíble que nadie lo haya pensado antes», dijo Morello.
«Lo que Guilherme y el equipo han inventado es una nueva forma de definir un ‘spin qubit’ que utiliza tanto el electrón como el núcleo del átomo. Crucialmente, este nuevo qubit puede ser controlado usando señales eléctricas, en lugar de señales magnéticas. Las señales eléctricas son significativamente más fáciles de distribuir y localizar en un chip electrónico».
Tosi dijo que el diseño elude un reto que se espera que enfrenten todos los qubits de silicio basados en el spin a medida que los equipos comienzan a construir conjuntos de qubits cada vez más grandes: la necesidad de espaciarlos a una distancia de sólo 10-20 nanómetros, o solo 50 átomos de separación.
«Si están demasiado cerca o demasiado lejos, el ‘entrelazamiento’ entre bits cuánticos -que es lo que hace que las computadoras cuánticas sean tan especiales- no ocurre», dijo Tosi.
Los investigadores de la UNSW ya lideran el mundo en la fabricación de qubits en esta escala, dijo Morello. «Pero si queremos hacer un arsenal de miles o millones de qubits tan cerca, significa que todas las líneas de control, la electrónica de control y los dispositivos de lectura deben fabricarse también en esa escala nanométrica, y con ese paso y esa densidad de electrodos. Este nuevo concepto sugiere otro camino.»
En el otro extremo del espectro se encuentran los circuitos superconductores – perseguidos, por ejemplo, por IBM y Google – y las trampas de iones. Estos sistemas son grandes y fáciles de fabricar, y actualmente están liderando el camino en el número de qubits que pueden ser operados. Sin embargo, debido a sus dimensiones más grandes, a largo plazo pueden enfrentar desafíos cuando intentan ensamblar y operar millones de qubits, como lo requieren los algoritmos cuánticos más útiles.
«Nuestro nuevo enfoque basado en silicio se encuentra justo en el punto ideal», dijo Morello, profesor de ingeniería cuántica de la UNSW. «Es más fácil de fabricar que los dispositivos a escala atómica, pero aún así nos permite colocar un millón de qubits en un milímetro cuadrado».
En el qubit de un solo átomo utilizado por el equipo de Morello, y que aplica el nuevo diseño de Tosi, se cubre un chip de silicio con una capa de óxido de silicio aislante, sobre cuya parte superior se apoya un patrón de electrodos metálicos que funcionan a temperaturas cercanas al cero absoluto y en presencia de un campo magnético muy fuerte.
El núcleo central es un átomo de fósforo, del cual el equipo de Morello ha construido previamente dos qubits funcionales utilizando un electrón y el núcleo del átomo. Estos qubits, tomados individualmente, han demostrado tiempos de coherencia de récord mundial.
El avance conceptual de Tosi es la creación de un tipo de qubit completamente nuevo, utilizando tanto el núcleo como el electrón. En este enfoque, se define un estado «0» cuando el giro del electrón está hacia abajo y el giro del núcleo hacia arriba, mientras que el estado «1» es cuando el giro del electrón está hacia arriba, y el giro nuclear está hacia abajo.
«Lo llamamos el qubit’ flip-flop'», dijo Tosi. «Para operar este qubit, hay que extraer el electrón un poco del núcleo, usando los electrodos de la parte superior. Al hacerlo, también creas un dipolo eléctrico.»
«Este es el punto crucial», añade Morello. «Estos dipolos eléctricos interactúan entre sí a distancias bastante grandes, una buena fracción de un micrón o 1000 nanómetros.
«Esto significa que ahora podemos separar mucho más los qubits de un solo átomo de lo que antes se creía posible», continuó. «Así que hay mucho espacio para intercalar los componentes clásicos clave como interconexiones, electrodos de control y dispositivos de lectura, manteniendo la naturaleza atómica precisa del bit cuántico».
Morello calificó el concepto de Tosi de tan significativo como Bruce Kane, el seminal artículo de 1998 en Nature. Kane, luego investigador asociado senior de la UNSW, se topó con una nueva arquitectura que podría hacer realidad un ordenador cuántico basado en silicio, lo que desencadenaría la carrera de Australia.
«Como en el trabajo de Kane, ésta es una teoría, una propuesta: el qubit aún no se ha construido», dijo Morello. «Tenemos algunos datos experimentales preliminares que sugieren que es totalmente factible, así que estamos trabajando para demostrarlo. Pero creo que esto es tan visionario como el trabajo original de Kane».
La construcción de un ordenador cuántico se ha denominado la «carrera espacial del siglo XXI», un reto difícil y ambicioso con el potencial de entregar herramientas revolucionarias para hacer frente a cálculos que de otro modo serían imposibles, con una plétora de aplicaciones útiles en el sector sanitario, la defensa, las finanzas, la química y el desarrollo de materiales, la depuración de software, el sector aeroespacial y el transporte. Su velocidad y poder radican en el hecho de que los sistemas cuánticos pueden albergar múltiples «superposiciones» de diferentes estados iniciales, y en el espeluznante «enredo» que sólo ocurre a nivel cuántico las partículas fundamentales.
«Se necesitará una gran ingeniería para llevar la computación cuántica a la realidad comercial, y el trabajo que vemos en este extraordinario equipo pone a Australia en el asiento del conductor», dijo Mark Hoffman, Decano de Ingeniería de la UNSW. «Es un gran ejemplo de cómo la UNSW, al igual que muchas de las universidades de investigación más importantes del mundo, se encuentra hoy en el corazón de un sofisticado sistema de conocimiento global que está dando forma a nuestro futuro».
El equipo de la UNSW ha llegado a un acuerdo de 83 millones de dólares australianos entre la UNSW, el gigante de las telecomunicaciones Telstra, el Commonwealth Bank de Australia y los gobiernos de Australia y Nueva Gales del Sur para desarrollar, para el año 2022, un prototipo de circuito integrado cuántico de silicio de 10 bits, el primer paso en la construcción de la primera computadora cuántica del mundo en silicio.
En agosto, los socios lanzaron Silicon Quantum Computing Pty Ltd., la primera empresa de computación cuántica de Australia, para avanzar en el desarrollo y comercialización de las tecnologías únicas del equipo. El Gobierno de Nueva Gales del Sur prometió 8,7 millones de dólares australianos, 25 millones de dólares de los EE. UU., 14 millones de dólares australianos para el Banco del Commonwealth, 10 millones de dólares australianos para Telstra y 25 millones de dólares australianos para el Gobierno federal.
Ampliar en: EurekAlert!
![]()

autobus las palmas aeropuerto cetona de frambuesa