Actualidad informática
Noticias y novedades sobre informática
Gran impulso a ‘BigData’ y la computación cognitiva en el Reino Unido
Después del compromiso del Gobierno británico para ampliar el Centro Hartree en Daresbury en los próximos cinco años, IBM proporcionará el mayor apoyo al proyecto con un paquete de tecnología y conocimientos, valorados en 200 millones de libras esterlinas.
Continuar en: Blasting.News

Computación cognitiva en base a Big Data

Watson es sobre Big Data. Se trata de la absorción de grandes cantidades de información sobre temas específicos como – medicina, leyes, viajes, comercio minorista, metalurgia, petróleo y el gas, etc. lo que sea – permitiendo al usuario consultar los datos para buscar patrones que ayuden en el diagnóstico, ayuda a encontrar argumentos legales, tomar una decisión sobre dónde perforar para obtener petroleo, casi cualquier cosa.
Tomemos un ejemplo. Watson inicialmente está siendo probado como una ayuda a los médicos para hacer más rápidos y precisos los diagnósticos.¿Por qué la medicina?
1) Los investigadores médicos pueden leer como máximo unos pocos cientos de artículos médicos al año. Watson ha ingerido todos los 23 millones de artículos médicos en la Biblioteca Nacional de Medicina (MEDLINE).
2) Los errores médicos son ahora la tercera causa principal de muerte en los EE.UU., según IBM.
Watson está diseñado para interactuar con el historial médico del paciente, así como con los datos que el médico obtiene tras la anamnesis y exploración. Así que ante un paciente que llega con un diagnóstico difícil, el médico podría consultar Watson, que compararía los síntomas contra un vasto cuerpo de conocimiento médico para producir una serie de posibles diagnósticos.Esto es particularmente valioso cuando se trata de enfermedades raras en las que es probable que el médico tenga poco conocimiento de la enfermedad o sus síntomas.
Fragmento traducido de Three years after ‘Jeopardy,’ IBM gets serious about Watson por Bob Pisani de CNBC
![]()
Predicción del crimen gracias a «big data»

Las juntas de libertad condicional, en más de la mitad de los estados de Estados Unidos, usan predicciones basadas en el análisis de datos. En Los Ángeles usan el análisis de datos masivos para seleccionar las calles, grupos e individuos que tienen más probabilidades de verse involucrados en crímenes. Algo similar al programa Blue CRUSH (por las siglas Reducción el Crimen Utilizando el Historial Estadístico) que se emplea en la ciudad de Memphis, Tennessee.
En Richmond, Virginia, la policía correlaciona los datos sobre crímenes con la información de fechas de conciertos, acontecimientos deportivos, e incluso sobre cuándo pagan las nóminas a sus empleados las grandes compañías de la ciudad.
A medida que se incrementan los datos de que disponemos sobre los individuos y sus relaciones con los diferentes elementos del mundo, ya sea gracias a sus interacciones con su smartphone (GPS, etc.) o las huellas digitales dejadas a través de Internet, se podrán establecer correlaciones en base a datos masivos que nos dirán muchas cosas acerca de cuándo y cómo se producen los crímenes.
Ya hay un proyecto de investigación desarrollado bajo el amparo del Departamento de Seguridad Interior de Estados Unidos llamado FAST (Tecnología de Exploración de Futuros Atributos) que tratará de identificar a los potenciales terroristas monitorizando los indicadores vitales, el lenguaje corporal y otros patrones fisiológicos.
Viktor Mayer-Schönberger afirma en su libro Big Data:
Si las predicciones basadas en datos masivos fueran perfectas, si los algoritmos pudieran prever nuestro futuro con infalible claridad, no tendríamos elección para obrar en el futuro. Nos comportaríamos exactamente a tenor de lo predicho. De ser posibles las predicciones perfectas, quedaría negada la voluntad humana, nuestra capacidad de vivir libremente nuestras vidas. Y, además, no sin ironía, al privarnos de elección nos librarían de toda responsabilidad. Por supuesto, la predicción perfecta es imposible. Antes bien, el análisis de datos masivos lo que predecirá es que, para un individuo específico, hay cierta probabilidad de que tenga un comportamiento futuro determinado. Véase, por ejemplo, la investigación llevada a cabo por Richard Berk, profesor de estadística y criminología de la universidad de Pensilvania. (…) Berk sostiene que puede predecir un futuro asesino entre los presos en libertad condicional con una probabilidad de acierto mínima del 75 por 100. No está mal. Sin embargo, también significa que si los comités de libertad condicional se basan en el análisis de Berk, se equivocarán una de cada cuatro veces, y eso no es poco.
Una sociedad semejante sería más segura, pero también se destruiría la presunción de inocencia, el principio básico de nuestro sistema legal y de nuestro sentido de lo que es justo.
Los datos masivos son útiles para comprender el riesgo presente y futuro, y para ajustar nuestras acciones en consonancia. Sus predicciones ayudan a pacientes y aseguradoras, prestamistas y consumidores. Pero no nos dicen nada acerca de la causalidad. En cambio, asignar “culp” (culpabilidad individual) requiere que las personas a las que juzgamos hayan elegido actuar de determinada manera. Su decisión debe ser causa de la acción subsiguiente. Precisamente porque los datos masivos están basaos en correlaciones, constituyen una herramienta del todo inadecuada para juzgar la causalidad y asignar, pues, la culpabilidad individual.
Fuente: Xataka ciencia
Licencia CC
![]()
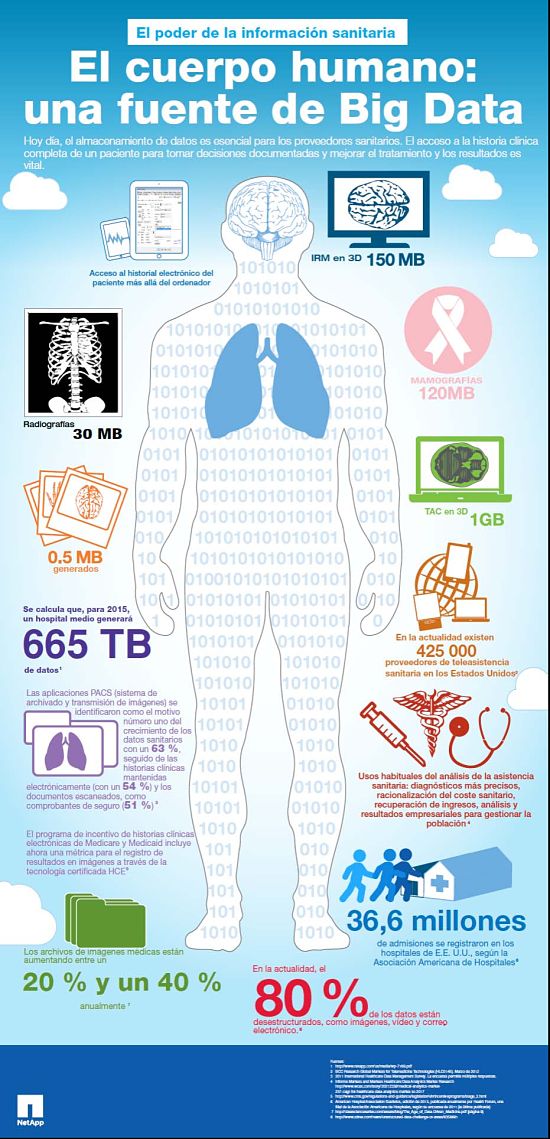
Logran reconstruir lenguas antiguas mediante software

Científicos de la UC Berkeley y de la Universidad de British Columbia han creado un software que es capaz de reconstruir lenguas antiguas mediante software, haciéndolo de manera más rápida que los humanos. Estas lenguas antiguas son llamadas «protolenguas», las cuales son las antepasadas de las lenguas que conocemos hoy en día y de las cuales han evolucionado. De entre estas protolenguas podemos destacar el Protoindoeuropeo, el Proto-afroasiático y el Protoaustronesio, que es la lengua que se ha usado en el estudio. El Protoaustronesio ha dado lugar a las lenguas que se hablan en el Sudeste Asiático, el Pacífico, zonas de Asia continental y Australasia.
Aprovechando las ventajas del Big Data y la computación los científicos quisieron probar que el software funcionaba y para ello cogieron 637 lenguas de las que se hablan ahora en Asia y la zona Pacífico y con ella recrearon la lengua común de la cual vienen todas ellas. Este software usa razonamiento probabilístico y busca dentro de la lógica evolutiva y las estadísticas para reconstruir el pasado.
De estas 637 lenguas se analizó una base de datos de unas 140.000 palabras para llevar a cabo la reconstrucción del Protoautronesio. Luego se comparó el resultado con el que ya tenían del trabajo de lingüistas y les salió una precisión del 85%, pero eso sí, en mucho menos tiempo.
Y es que hasta ahora todo el trabajo se hacía de manera manual con lingüistas especializados. Según palabras de Dan Klein, profesor asociado de la UC Berkeley:
Lleva mucho tiempo para los humanos el hecho de revisar todos los datos. Hay miles de lenguas en el mundo, con miles de palabras cada una ya sin tener en cuenta los ancestros de estas lenguas. Necesitaríamos cientos de años para entrar en detalle en cada lengua y hacer referencias cruzadas entre todos los cambios que han pasado durante el tiempo. Pero en esto es en donde los ordenadores brillan.
Los que me apasiona de este sistema es que podremos coger todas las grandes ideas que los lingüistas han tenido sobre la reconstrucción histórica y las podremos automatizar: más datos, más palabras y más lenguas en menos tiempo.
De momento, con la ayuda de este software podemos esperar que se avance más rápido en el descubrimiento de estas lenguas antiguas. Lo que sigue siendo un misterio es si se podrá ir más atrás y descubrir si hubo una vez una primera lengua de la cual salieron todas las demás.
Fuente: ALT1040
Bajo licencia Creative Commons
![]()
Cinco mitos acerca Big Data

Con la cantidad de expectación en torno a Big Data es fácil olvidar que sólo estamos en los inicios. Más de tres exabytes de datos nuevos se crean cada día, y la firma de investigación IDC estima que 1200 exabytes de datos se generarán este año.
La expansión de los datos digitales se ha prolongado durante más de una década y para aquellos que han hecho un poco de investigación, entienden que las referencias de grandes cantidades de datos son mucho más que Google, eBay o Amazon y medianas series de datos. La oportunidad para una empresa de cualquier tamaño para obtener ventajas a partir de Big Data se deriva de la agregación de datos, extracción de datos y metadatos – los bloques de construcción fundamentales para el análisis de los negocios del mañana. En conjunto, estos datos ofrecen una oportunidad sin precedentes.
Sin embargo, a pesar de la amplitud de Big Data que se está discutiendo, parece que todavía es un misterio muy grande para muchos. De hecho, fuera de los expertos que tienen un gran dominio de este tema, los malentendidos en torno a Big Data parecen haber llegado a proporciones míticas.
Éstos son los cinco mitos:
1. Big Data es sólo volumen masivo de datos
El volumen es sólo un elemento clave en la definición de Big Data, y es posiblemente el menos importante de los tres elementos. Los otros dos son la variedad y la velocidad. En conjunto, estas tres «V» de Big Data se postularon inicialmente por Doug Laney de Gartner en un informe de 2001.
En términos generales, los expertos consideran petabytes de volúmenes de datos como punto de partida para Big Data, aunque este indicador de volumen es un blanco móvil. Por lo tanto, mientras que el volumen es importante, las dos siguientes «V» son mejores indicadores individuales.
Variedad se refiere a datos de muchos tipos diferentes de archivos que son importantes para gestionar y analizar más a fondo, pero para los que las bases de datos relacionales tradicionales se adaptan mal. Algunos ejemplos de esta variedad incluyen los archivos de sonido, películas, imágenes, documentos, datos de localización geográfica, registros web y cadenas de texto.
La velocidad es la tasa de cambio en los datos y la rapidez con que se deben utilizar para crear valor real. Las tecnologías tradicionales son especialmente poco adecuadas para el almacenamiento y el uso de alta velocidad de los datos. Por lo tanto se necesitan nuevos enfoques. Si los datos en cuestión se crean y se agregan muy rápidamente se deben utilizar con rapidez para descubrir patrones y problemas, cuanto mayor es la velocidad es más probable que se tenga una oportunidad para Big Data.
2. Big Data significa Hadoop
Hadoop Apache es el marco de software de código abierto para trabajar con Big Data. Fue derivado de tecnología de Google y llevado a la práctica por Yahoo y otros. Sin embargo, Big Data es muy variada y compleja, para única solución para todo. Aunque sin duda Hadoop ha logrado el reconocimiento y gran renombre, es sólo una de las tres clases de tecnologías muy apropiadas para el almacenamiento y la gestión de Big Data. Las otras dos clases son NoSQL y procesamiento masivo paralelo (MPP). Ejemplos de MPP Big Data son Greenplum EMC, IBM Netezza, y Vertica de HP.
Además, Hadoop es un marco de software, lo que significa que incluye una serie de componentes que fueron diseñados específicamente para resolver en gran escala el almacenamiento distribuido de datos, análisis y tareas de recuperación. No todos los componentes Hadoop son necesarios para una solución Big Data, y algunos de estos componentes pueden ser sustituido por otras tecnologías que complementan mejor las necesidades de un usuario. Un ejemplo es la distribución de Hadoop MAPR, que incluye NFS como una alternativa a HDFS, y ofrece un completo acceso aleatorio, de lectura/escritura del sistema de archivos.
3. Big Data significa datos no estructurados
El término «estructurado» es impreciso y no tiene en cuenta las muchas y sutiles estructuras típicamente asociadas con los tipos de Big Data. Además, los Big Data bien pueden tener diferentes tipos de datos dentro del mismo conjunto que no contienen la misma estructura.
Por lo tanto, Big Data es, probablemente, mejor llamado «multi-estructurado», ya que podría incluir cadenas de texto, documentos de todo tipo, archivos de audio y vídeo, metadatos, páginas web, mensajes de correo electrónico, feed de medios sociales de comunicación, datos de formularios, y así sucesivamente. El rasgo común de estos tipos de datos variados es que el esquema de datos no es conocido o se define cuando los datos se capturan y se almacenan. Más bien, un modelo de datos se aplica a menudo a la vez que se utilizan los datos.
4. Big Data es para feeds de medios de comunicación social y análisis de sentimiento
En pocas palabras, si una organización necesita analizar el tráfico web en términos generales, registros del sistema de TI, sentimiento del cliente, o cualquier otro tipo de datos digitales, que se están creando en volúmenes récord cada día, Big Data ofrece una manera de hacer esto. A pesar de que los pioneros de Big Data han sido los más grandes, basadas en la Web, las compañías de medios sociales -Google, Yahoo, Facebook- que era el volumen, variedad y velocidad de los datos generados por los servicios que requieren una solución radicalmente nueva en lugar de la necesidad de analizar feeds social o el sentimiento público de audiencias.
Ahora, gracias a la potencia de los ordenadores cada vez mayor (a menudo basados en la nube), software de código abierto (por ejemplo, la distribución de Apache Hadoop), y un tratamiento moderno de los datos que puedan generar valor económico si se utilizan adecuadamente, hay un sinfín de usos y aplicaciones Big Data. Un primer favorito y breve Big Data, que contiene algunos de los usos que hacen pensar, fue publicado como un artículo a principios de este año en la revista Forbes.
5. NoSQL significa No SQL
NoSQL significa «no sólo» SQL porque este tipo de bases de datos ofrecen acceso a un dominio específico y técnicas de consulta, de SQL o interfaces de tipo SQL. Tecnologías en esta categoría NoSQL incluyen bases de datos de claves, bases de datos orientados a documentos, bases de datos de gráficos, grandes estructuras planas, y almacenamiento en caché de bases de datos. Los métodos específicos de acceso nativo a los datos almacenados proporcionan un enfoque rico, de baja latencia, normalmente a través de una interfaz propietaria. El acceso SQL tiene la ventaja de familiaridad y compatibilidad con muchas herramientas existentes. Aunque esto es por lo general conlleva algún gasto de latencia impulsado por la interpretación de la consulta del «lenguaje nativo» del sistema subyacente.
Por ejemplo, Cassandra, la popular tienda de claves de código abierto valor ofrecido en forma comercial por DataStax, no sólo incluye las API nativas para el acceso directo a los datos de Cassandra, pero CQL (interfaz del tipo SQL) es su nuevo mecanismo de acceso preferido. Es importante elegir la tecnología NoSQL adecuada para satisfacer tanto el problema de negocio y tipo de datos y de las muchas categorías de tecnologías de NoSQL ofrecen un montón de opciones.
Fuente: Mashable business
![]()

autobus las palmas aeropuerto cetona de frambuesa