Actualidad informática
Noticias y novedades sobre informática
Los medios sociales en internet aceleran la ciencia

A principios de junio de 2011, en una conferencia sobre bioinformática celebrada en las afueras de Cambridge (Reino Unido), Jennifer Gardy, epidemióloga de la Universidad de Columbia Británica, observó cómo se producía una tormenta en Twitter. La pequeña población mundial de epidemiólogos genómicos está sentada en esta sala de conferencias «, recuerda, y todos ellos parecían estar despidiendo tweets tan rápido como podían componerlos. Apenas unas semanas antes, habían salido a la luz informes de que una nueva y mortal variante de E. coli estaba infectando a la gente en algunas partes de Alemania. Mientras que los epidemiólogos se reunían en la sala, los investigadores del Instituto de Genómica de Beijing (BGI) anunciaron en Twitter que acababan de publicar una secuencia sin ensamblar del genoma de la cepa. Por pura coincidencia, los genetistas en la conferencia acababan de discutir la secuenciación del genoma entero como una herramienta forense en epidemiología. De repente, se les entregó un caso abierto.
Gardy estaba sentado en la primera fila al lado del Nick Loman de la Universidad de Birmingham, quien ayudó a organizar la reunión, la conferencia Wellcome Trust sobre Bioinformática Aplicada y Microbiología de Salud Pública. Vemos el tweet de BGI subir, y Nick inmediatamente lo agarra «, recuerda Gardy.
Loman envió los datos a un servidor suyo que reúne genomas, cosiendo breves lecturas en un todo coherente para ser analizado con cualquier número de técnicas bioinformáticas. Luego escribió un artículo en el blog y envió un tweet, poniendo el genoma reunido suelto en línea. Durante el resto de la conferencia, durante las presentaciones y en las pausas para tomar café en el vestíbulo, los investigadores abrieron sus cajas de herramientas genómicas personales para investigar el genoma. Ellos y otros investigadores de todo el mundo compartieron y discutieron sus hallazgos entre ellos en tiempo real en Twitter. Incluso después de la conferencia, los análisis del genoma E. coli continuaron apareciendo, de tal manera que Loman instaló un wiki para recopilar la información. Menos de dos meses después, Loman y otros publicaron un artículo basado en parte en este análisis genómico de fuentes multitudinarias (N Engl J Med, 365:718-24,2011).
Veinticuatro horas después de la liberación del genoma, se había reunido; dos días después de su diseminación, se le había asignado un tipo de secuencia existente «, decía el documento. Cinco días después de la publicación de los datos de la secuencia, habíamos diseñado y publicado secuencias de diagnóstico específicas de la cepa, y en una semana, dos docenas de reportes habían sido archivados en un wiki de código abierto.
Twitter, en ese momento, se había convertido en una plataforma de medios sociales establecida, pero los científicos todavía se sentían entusiasmados con la idea de tener intercambios técnicos significativos utilizando misivas de 140 caracteres. Para algunos, sin embargo, esta herramienta de trabajo en red y de intercambio demostró ser muy prometedora para la investigación científica. Ahora, los científicos en campos de rápida evolución y basados en datos están descubriendo que estos foros en línea permiten la difusión en tiempo real de su trabajo. Compartir la investigación sobre medios sociales también encaja con el creciente interés de la comunidad en acelerar la publicación científica, como lo demuestra una serie de nuevos servidores de preimpresión.
Twitter es el lugar donde realmente escucho a la gente hablar de ciencia «, dice Richard Sever, editor ejecutivo de Cold Spring Harbor Perspectives y cofundador de bioRxiv, el servidor preimpreso de bioRxiv. «Eso ha abierto los ojos para algunas personas. … … … De repente, gente seria, científicos serios, especialmente en genómica, empezaron a unirse. Y están teniendo serios debates «.
Ampliar en: The Scientist
![]()

Ordenadores orgánicos de ADN podrían procesar datos en nuestros cuerpos
Siempre imaginamos dispositivos electrónicos que se fabrican a partir de chips de silicio, con la que los ordenadores almacenan y procesar información en forma de dígitos binarios (ceros y unos) representados por pequeñas cargas eléctricas. Pero no necesariamente tiene que ser de esta manera: Entre las alternativas al silicio están los medios orgánicos tales como el ADN.
La computación de ADN se demostró por primera vez en 1994 por Leonard Adleman, que codificó y se resolvió el problema del viajante, un problema de matemáticas para encontrar la ruta más eficiente para un vendedor, entre ciudades, en su totalidad en el ADN.
EL ácido desoxirribonucleico, ADN, puede almacenar grandes cantidades de información codificada como secuencias de las moléculas, conocidos como nucleótidos, citosina (C), guanina (G), adenina (A), o timina (T). La complejidad y la enorme variación de los códigos genéticos de diferentes especies demuestra cuánta información puede ser almacenada en el ADN, que se codifica mediante CGAT, y esta capacidad puede ser objeto de uso por parte de la informática. Las moléculas de ADN se pueden emplear para procesar la información, utilizando un proceso de unión entre los pares de ADN conocido como hibridación. Esto lleva a cadenas simples de ADN como entrada y produce hebras de ADN a través de transformación como salida.
Desde el experimento de Adleman, muchas «circuitos» basados en ADN se han propuesto para implementar métodos computacionales, tales como la lógica de Boole, fórmulas aritméticas y cálculo de redes neuronales. Llamada programación molecular, este enfoque aplica conceptos y diseños habituales de la computación a escala nanométrica, siendo apropiado para trabajar con el ADN.
En esta «programación» lo que tiene sentido es realmente la bioquímica. Los «programas» creados son en base a la selección de moléculas que interactúan de una manera que logran un resultado específico en el proceso de autoensamblaje de ADN, donde colecciones desordenadas de moléculas espontáneamente interactúan para formar la disposición deseada de filamentos de ADN.
‘Robots’ de ADN
El ADN también se puede utilizar para controlar el movimiento, lo que permite dispositivos basados en la nanomecánica que usan el ADN. Esto se logró por primera vez por Bernard Yurke y sus colegas en 2000, que crearon a partir de hebras de ADN un par de pinzas que se abrían y pellizcaban. Experimentos posteriores, como el de Shelley Wickham y colegas en 2011 y en el laboratorio de Andrew Turberfield en Oxford demostraron que máquinas para caminar nanomoleculares hechas enteramente de ADN, podrían recorrer rutas establecidas.
Una posible aplicación es que un nanorobot caminante de ADN podría progresar a lo largo de pistas de toma de decisiones y dar la señal cuando se alcanza el final de la pista, lo que indica que el cómputo ha terminado. Al igual que los circuitos electrónicos se imprimen en tarjetas de circuitos, las moléculas de ADN se podrían utilizar para imprimir pistas similares dispuestas en árboles de decisión lógicos en un chip de ADN, y las enzimas se utilizarían para controlar la decisión de ramificación a lo largo del árbol, haciendo que el caminante tome una pista u otra.
Los caminantes de ADN también pueden transportar carga molecular, y así podrían ser utilizados para administrar medicamentos dentro del cuerpo.
¿Por qué la computación de ADN?
Entre las muchas características atractivas de las moléculas de ADN, se incluye su tamaño (ancho 2 nm), programabilidad y alta capacidad de almacenamiento – mucho mayor que sus homólogos de silicio. ADN también es versátil, barato y fácil de sintetizar, y la computación con ADN requiere mucha menos energía que los procesadores de silicio eléctricos.
Su desventaja es la velocidad: en la actualidad lleva varias horas para calcular la raíz cuadrada de un número de cuatro dígitos, algo que una computadora tradicional podría calcular en una centésima de segundo. Otro inconveniente es que los circuitos de ADN son de un solo uso, y necesitan ser recreado para ejecutar el mismo cálculo de nuevo.
Quizás la ventaja más grande de ADN a través de circuitos electrónicos es que puede interactuar con su entorno bioquímico. La computación con moléculas implica reconocer la presencia o ausencia de ciertas moléculas, y por lo que una aplicación natural de la informática de ADN es llevar esa capacidad de programación al ámbito de biosensores ambientales o de la entrega de medicamentos y terapias dentro de los organismos vivos.
Programas de ADN ya se han empleado en usos médicos, tales como el diagnóstico de la tuberculosis. Otro uso propuesto es un «programa» nano-biológica por Ehud Shapiro, del Instituto de Ciencia Weizmann en Israel, denominado el «médico de la célula» que se dirige a moléculas cancerígenas. Otros programas de ADN para aplicaciones médicas linfocitos diana (un tipo de glóbulo blanco), que se definen por la presencia o ausencia de ciertos marcadores de células y así se pueden detectar de forma natural con la lógica booleana verdadera/falso. Sin embargo, se requiere más esfuerzo antes de que podamos inyectar drogas inteligentes directamente en los organismos vivos.
El futuro de la computación de ADN
Tomado en términos generales, el cómputo de ADN tiene un enorme potencial de futuro. Su gran capacidad de almacenamiento, bajo coste energético, facilidad de fabricación que explota el poder de autoensamblaje y su fácil afinidad con el mundo natural es una entrada a la informática a escala nanométrica, posiblemente a través de diseños que incorporan ambos componentes moleculares y electrónicas. Desde su creación, la tecnología ha avanzado a gran velocidad, la entrega de diagnósticos en el punto de atención y prueba de concepto de medicamentos inteligentes – aquellos que pueden tomar decisiones de diagnóstico sobre el tipo de terapia para entregar.
Hay muchos desafíos, por supuesto, que hay que abordar de manera que la tecnología puede avanzar desde el concepto de prueba de drogas inteligentes: la fiabilidad de los caminantes de ADN, la solidez del autoensamblaje de ADN, y la mejora de la entrega de fármacos. Pero tras un siglo de investigación la informática tradicional está bien situada para contribuir al desarrollo de la informática de ADN a través de nuevos lenguajes de programación, abstracciones, y técnicas de verificación formal – técnicas que ya han revolucionado el diseño de circuitos de silicio, y puede ayudar a poner en marcha la computación orgánica por el mismo camino.
Fuente: The Conversation
![]()
¿Cuánto ADN hay en la Tierra y cuánta información contiene?
 ¿Cuánto ADN hace falta, entonces, para formar un ser humano? ¿Cuánta información procesa cada ser vivo? Es más, ¿Cuánto ADN en total habrá en el mundo en el que vivimos? Tanto en capacidad de guardar información como en cantidad, las cifras son sencillamente impresionantes.
¿Cuánto ADN hace falta, entonces, para formar un ser humano? ¿Cuánta información procesa cada ser vivo? Es más, ¿Cuánto ADN en total habrá en el mundo en el que vivimos? Tanto en capacidad de guardar información como en cantidad, las cifras son sencillamente impresionantes.
Supongamos que la tierra es un gran sistema de computación. Esto precisamente es lo que han hecho unos investigadores del centro de Astrobiología y la Universidad de Edimburgo. Todo con la intención de medir cuánto ADN podría haber sobre la faz de la Tierra. Según sus estimaciones, en masa, el ADN existente en nuestro pequeño planeta es de unas 5 por 10 elevado a diez (5×10^10) toneladas de ADN. Es decir, unos 1000 millones de enormes contenedores de carga. Lo que parece muchísimo para algo que mide tan poco que no podemos ver a simple vista. Pero si esta cifra no te impresiona, tal vez lo haga su implicación. Puesto que el ADN es la unidad fundamental de información y su misión es almacenarla procesarla, esto 1000 millones de contenedores suponen una capacidad de unas 5.3 × 10^31 (±3.6 × 10^31) megabases (Mb, que equivalen a un millón de pares de bases).
La cantidad de información almacenada excede cualquier posibilidad de imaginarla. Pero para que nos hagamos una idea, el ADN de la Tierra es unas 10 elevado a las 22 (10^22) veces más rápido procesando que el superordenador más rápido de la Tierra, el Tianhe-2 chino, que cuenta con unos 33.86 PetaFLOPS. Esto supone, en concreto, un poder de computación de unos 10 elevado a 15 (10^15) yottaNOPS. Para quien no lo sepa, yotta significa a su vez 10 elevado a 24 (10^24). Además, necesitaríamos unos 10 elevados a la 21 (10^21) ordenadores como éste para almacenar toda la información que guarda el ADN en total. Aunque hasta ahora se había investigado muchísimo sobre la cantidad de ADN total existente en organismos, es la primera vez que alguien intenta estimar la capacidad en información relacionada con cuánto ADN existe.
Ampliar en: Conocer Ciencia
![]()
Lo nuevo en impresión en 3D, ojos artificiales, cráneos de plástico y un cuerpo humano entero
 La aparición de tintas orgánicas y materiales termoplásticos biológicos ha permitido la impresión de diferentes partes del cuerpo humano mediante el uso de impresoras 3D.
La aparición de tintas orgánicas y materiales termoplásticos biológicos ha permitido la impresión de diferentes partes del cuerpo humano mediante el uso de impresoras 3D.
Recientemente asistimos a la noticia de que médicos holandeses habían reemplazado casi la totalidad del cráneo de una paciente por una versión del mismo impreso en un material plástico biológico.
Otras partes del cuerpo humano como los ojos podrían ser pronto impresas mediante la tecnología 3D. Por ejemplo, se podría producir una copia de cada ojo con la única diferencia de una pequeña variación en el color del iris.
En otro sentido los escáneres faciales en 3D, también podrían ser empleados para la producción de prótesis faciales, utilizando polvo de almidón y silicona para producir réplicas de piezas faciales muy similares a una nariz o una oreja. Los beneficios serían increíbles al no tener que realizar moldes de la cara del paciente. En su lugar simplemente se escanearía la cara, resultando muchísimo más fácil.
Incluso una oreja podría ser reproducida mediante la impresión de un molde en 3D, utilizando geles y tintas con células vivas. Los productos de impresión son inyectados en células de bóvidos o en colágeno de rata. Posteriormente se incuban hasta que estén listos para posteriormente trasplantarlos a humanos.
¿Piel sintética?, la tinta sintética usada compuesta por enzimas y colágeno, una vez impresa se puede acomodar a las células de la piel en un injerto. La idea emplear estos cultivos celulares en zonas remotas devastadas por la guerra.
Autor: Carlos Alcalde
Fuente: XATAKA ciencia
![]()
Descubierto nuevo tipo de antibióticos, mediante computación

Un equipo de investigadores dirigido por Mayland Chang y Shahriar Mobashery, de la Universidad de Notre Dame, han descubierto una nueva clase de antibióticos para combatir bacterias tales como la meticilina – resistente Staphylococcus aureus (MRSA) y otras bacterias resistentes a los fármacos, que amenazan la salud pública. La investigación se publica en la Revista Journal of the American Chemical Society en un artículo titulado «Discovery of a New Class of Non-beta-lactam Inhibitors of Penicillin-Binding Proteins with Gram-Positive Antibacterial Activity«.
La nueva clase, denominada oxadiazoles, fue descubierto por rastreo y detección mediante ordenador y se ha mostrado prometedora en el tratamiento de MRSA en modelos de ratones con infección. Los investigadores que proyectaron 1,2 millones de compuestos, encontraron que el oxadiazol inhibe una proteína de unión a penicilina , PBP2a, y la biosíntesis de la pared celular que permite a la bacteria resistir otras medicinas. Los oxadiazoles también son eficaces cuando se toman por vía oral. Esta es una característica importante ya que sólo hay un antibiótico comercializado para MRSA que se pueden tomar por vía oral.
MRSA se ha convertido en un problema mundial de salud pública desde la década de 1960 debido a su resistencia a los antibióticos. Sólo en Estados Unidos, 278000 personas son hospitalizadas y 19000 mueren cada año por infecciones causadas por MRSA. Sólo tres fármacos actualmente son tratamientos efectivos, y la resistencia a cada uno de esos medicamentos ya existe.
Los investigadores han estado buscando una solución para MRSA durante años. «El profesor Mobashery ha estado trabajando en los mecanismos de resistencia durante mucho tiempo», dijo Chang. » A nuestro entender, en función de cuáles son los mecanismos, podemos diseñar estrategias para el desarrollo de compuestos contra MRSA».
«Mayland Chang y el descubrimiento de Shahriar Mobashery de una clase de compuestos frente a las bacterias resistentes a los medicamentos como el MRSA podrían salvar miles de vidas en todo el mundo. Estamos muy agradecidos por su liderazgo y persistencia en la lucha contra la resistencia a los medicamentos «, dijo Greg Crawford , decano de la Facultad de Ciencias de la Universidad de Notre Dame.
Información proporcionada por la Universidad de Notre Dame.
![]()
Hígado fabricado mediante impresión 3D

Una compañía pionera, Organovo, promete que el próximo año veremos el primer hígado artificial. La impresión 3D es una gran apuesta, en la que el sector privado y algunos grupos de investigación públicos han centrado sus esfuerzos. En este segundo caso, hace unos días unos científicos de la Universidad de Cambridge, lograron imprimir células ganglionares de la retina y células de la glía.Las células madre y la impresión 3D prometen revolucionar la medicina
Su éxito permitía que pudiéramos soñar con que algún día la impresión 3D pudiera ser usada en la regeneración de estructuras visuales dañadas por alguna enfermedad o accidente. Aunque no podemos decir todavía que las impresoras 3D servirían para curar la ceguera, lo cierto es que sus aplicaciones en medicina regenerativa son cada día más evidentes.
Dentro del sector privado, hay una compañía que destaca especialmente por el uso de la impresión 3D en biomedicina. Se trata de Organovo, una empresa fundada en 2003 a partir de los resultados de investigación del Dr. Thomas Boland en la Clemson University de Estados Unidos. Sus pioneros trabajos contaron con el apoyo de otras entidades académicas, como la University of Missouri o los propios Institutos Nacionales de Salud (NIH).
El pasado mes de octubre la compañía estadounidense anunció que había conseguido imprimir tejidos hepáticos, que habían presentado una actividad normal durante 40 días. Estos cultivos tridimensionales también respondían de manera fisiológica a determinados fármacos.
Por desgracia, contar con un cultivo hepático tridimensional no es lo mismo que construir un hígado artificial mediante impresión 3D. Para lograr realmente un órgano funcional, necesitamos también acoplar de alguna manera estructuras similares a vasos (arterias y venas), que pudieran mimetizar el riego sanguíneo que recibe un hígado de forma normal en nuestro organismo.
Organovo ha anunciado que ya es capaz de construir un auténtico sistema vascular mediante impresión 3D, noticia que facilitaría la llegada de un hígado artificial el próximo año. Una noticia excelente para la investigación biomédica, que ve en esta puntera tecnología una posible solución para los problemas de abastecimiento de órganos de trasplantes o incluso para la reparación de tejidos dañados tras una enfermedad o accidente.
Fuente: ALT1040
Licencia CC
![]()
Problemas excepcionales demandan ordenadores escepcionales

Las proteínas realizan la mayor parte del trabajo de la célula, catalizan la mayoría de las reacciones bioquímicas, inician y median las señales eléctricas en las neuronas y constituyen una parte importante de la estructura de nuestro cuerpo. Formadas por hasta varios miles de aminoácidos (de un conjunto de 20 tipos diferentes) encadenados entre ellos, las proteínas se pliegan bajo el efecto de fuerzas no covalentes entre diferentes partes de la molécula en formas con significado funcional; formas que no son estáticas, que cambian constantemente, al azar y también reaccionan a la influencia externa. Estos cambios conformacionales tienen un impacto en su función, lo que permite que las proteínas interactúen entre sí o con otras moléculas de señalización (hormonas, medicamentos …). El mal plegamiento de proteínas o modificaciones de los cambios conformacionales conducen a enfermedades, incluyendo la enfermedad de Alzheimer y Parkinson, y mucho dinero y esfuerzo se está poniendo en la comprensión de las estructuras de proteínas, caminos de plegado e interacciones con otras moléculas.
Varias herramientas experimentales se utilizan para estudiar la conformación de proteínas, pero todos están limitadas en su resolución espacial y temporal. En efecto, la más poderosa entre ellas, difracción de rayos X, sólo proporciona una instantánea de la estructura de las proteínas. Si queremos estudiar la dinámica de proteínas (como la conformación de una molécula cambia con el tiempo), entonces la simulación por ordenador ofrece una buena alternativa. Una simulación exacta requiere resolver las ecuaciones de la mecánica cuántica para moléculas grandes, pero esto es computacionalmente demasiado complicado para ser práctico. La dinámica molecular (MD) simula cada átomo de la molécula como evoluciona siguiendo las reglas de la mecánica clásica y campos de fuerza semi-empíricos. Las simulaciones MD se han utilizado desde mediados de los setenta para entender los procesos bioquímicos, y actualmente representan la mayor parte del tiempo asignado a ordenadores destinados a la investigación biomédica en los centros de supercómputo de la Fundación Nacional para la Ciencia, EE.UU..
A pesar de su popularidad, las simulaciones MD son computacionalmente costosas. La necesidad de captar las vibraciones de átomos rápidos requiere de pasos de cálculo de unos pocos femtosegundos, y cada paso involucra uno mil millones de operaciones para una molécula de cien mil átomos. Para simular un milisegundo en la vida de una única molécula de proteína se necesitan alrededor de mil millones de pasos y un sextillón (10 ^ 21) de operaciones. Como resultado, incluso utilizando los superordenadores más potentes disponibles, la mayoría de las simulaciones MD sólo estudian los procesos en tiempos de nanosegundos o microsegundos. Se necesitaría un tiempo excesivamente largo de supercomputadora para llegar a las escalas de tiempo de milisegundos en el que tienen lugar muchos cambios conformacionales de proteínas y sus interacciones. En un. Documento reciente Ron O. Dror y sus colegas de D. E. Shaw Research muestran estudios recientes que están superando este problema.
Una solución, el cálculo de las diferentes partes de la molécula en paralelo, ha demostrado ser particularmente difícil. Las innovaciones recientes en los algoritmos paralelos han mejorado parcialmente la situación, permitiendo agrupaciones de superordenadores para calcular en el plazo de tiempo de microsegundos. De hecho, en algunos problemas, parte de la simulación puede ser dividida en muchas trayectorias separadas cortas que se pueden ejecutar en paralelo en cientos de miles de ordenadores personales. Este es el proyecto Folding@Home, que permite a cualquier persona con un ordenador (o incluso una PlayStation moderna) y conexión a internet la oportunidad de donar tiempo de simulación y colaborar con la investigación científica. Más de cien estudios publicados se han producido gracias a esta iniciativa.
Los mayores avances en la optimización de simulación MD se han confeccionado siguiendo esa ruta de adaptar nuestras herramientas para la tarea. Esta es una solución bien conocida en ingeniería y en biología. Por ejemplo, los ojos se adaptan a las escenas que puedan ver, haciéndolos más eficientes, y los oídos a los sonidos que puedan escuchar. En la ingeniería del ordenador, las unidades de procesamiento gráfico (GPU) fueron diseñadas para operaciones con gráficos y en esa tarea es que superan a los procesadores generales mucho más potentes. Son particularmente un buen ejemplo del hecho de que el hardware de propósito integrado puede conducir a la computación más eficiente de problemas particulares.
La investigación de D. E. Shaw seguido esta idea en el diseño de una máquina específicamente diseñada para simulación MD, llamada Anton. Sus chips, contienen un «conjunto de unidades aritméticas de lógica cableada para el cálculo de las interacciones de partículas», están conectados entre ellos de una manera que evita el uso de la gestión de memoria que es computacionalmente cara. Anton lleva a cabo todas sus operaciones en circuitos construidos para tal fin, a diferencia de proyectos anteriores (FASTRUN, Motor MD, MDGRAPE), donde sólo las partes más costosas computacionalmente de la simulación fueron optimizados. Gracias a esta arquitectura especial, Anton puede realizar 20 microsegundos de una simulación MD de todos los átomos por día, alrededor de 100 veces más rápido que cualquier otra alternativa.
En su opinión, los desarrolladores de Anton sugiern problemas que son susceptibles de beneficiarse de los avances en este campo. Mejores simulaciones MD ayudarán en el desarrollo de fármacos, mediante la producción de predicciones más precisas de la eficacia con que se unen a las proteínas, y en el diseño de proteínas para ser utilizadas como biosensores para el cáncer o anticuerpos. Además, el estudio de la dinámica de otras moléculas grandes tales como ARN y ADN también se beneficiarán de la construcción de ordenadores especiales.
Fuente: Exceptional problems demand exceptional computers en Mapping Ignorance.
![]()
Los posibles ordenadores del futuro

Un entretenimiento común es imaginar qué podrán hacer los ordenadores del futuro… y la imaginación es el único límite. Pero todas las especulaciones parten de que vamos a tener máquinas capaces de funcionar a mucha mayor capacidad, con mucho mayor almacenamiento de datos. El problema es cómo conseguirlo.
Quizá las moléculas vivientes, como el ADN, puedan ser las sucesoras del ordenador electrónico que ha dominado nuestra vida desde la década de 1970. Ya en 2003, el científico israelí Ehud Shapiro consiguió crear un “ordenador” biomolecular en el que moléculas de ADN y enzimas que hacen que el ADN produzca determinadas proteínas podrían resolver problemas como la identificación de ciertos tumores en sus etapas más tempranas. Un ordenador que utilizara cadenas de ADN para realizar las operaciones de proceso de datos podría ser, en teoría, miles de veces más poderoso y rápido que los mejores procesadores electrónicos de hoy en día, al menos en ciertos tipos de procesos.
En el terreno de los posibles ordenadores biológicos, también se trabaja en uno formado por neuronas, es decir, las células del sistema nervioso de los animales. En 1999 se desarrolló el primero, formado por una serie de neuronas procedentes de sanguijuelas, donde cada neurona representaba un número y las operaciones se realizaban conectando a las neuronas entre sí. Uno de los atractivos de los ordenadores de neuronas es, según Bill Ditto, creador de este sistema pionero, que hipotéticamente pueden alcanzar soluciones sin tener todos los datos, a diferencia de los ordenadores electrónicos. Al poder realizar sus propias conexiones, en cierto modo estas neuronas podrían “pensar” de modo análogo, a grandes rasgos, a como pensamos nosotros cuando tratamos de resolver un problema sin datos suficientes.
Pero el área de trabajo más intenso como alternativa al ordenador electrónico es la informática cuántica, que trabaja a niveles subatómicos.
En el mundo a nuestra escala, los ordenadores trabajan con un lenguaje binario, es decir, que cada elemento de su lógica o “bit” sólo puede tener uno de dos valores: 1 o 0. Las operaciones de proceso de datos van transformando cada bit hasta que llega a un valor final que es la solución del problema.
Pero en un ordenador cuántico no tenemos bits sino qbits (bits cuánticos), que debido a las propiedades de las partículas elementales que describe la mecánica cuántica, pueden tener un valor de 0, de 1 o de una“superposición” de esos dos valores, es decir, ambos a la vez. Pero si tomamos un par de qbits, pueden estar cualquier superposición de cuatro estados. Así, la cantidad de qbits para representar la información en un ordenador cuántico es mucho menor que la cantidad de bits en uno electrónico y la cantidad de procesos que puede realizar es mucho mayor y a mayor velocidad, explorando diversas opciones para cada problema.
Los primeros ordenadores cuánticos comerciales han sido ya adquiridos por una empresa aeroespacial y por el gigante de las búsquedas en Internet, Google. La decisión se tomó después de constatar que el ordenador cuántico resolvía en medio segundo un problema que le tomaba media hora a uno de los más poderosos ordenadores industriales existentes.
Por más que nos pueda asombrar cuánto ha avanzado la informática desde sus inicios en 1946, es posible que apenas estemos por salir de la infancia de los ordenadores. Y el futuro será todo, menos predecible.
Ampliar en: Los expedientes Occam
![]()
Craig Venter próximo a crear vida sintética

Por primera vez estamos cerca de crear vida artificial desde el principio. Así lo afirma Craig Venter, fundador del J. Craig Venter Institute en Rockville, Maryland (EE.UU.), y famoso por crear la primera célula con un genoma sintético.
«Creemos que estamos cerca, pero no hemos presentado un documento todavía», dijo en la cumbre mundial de los grandes retos en Londres esta semana.
Venter anunció en 2010 que había traído a la vida de una versión casi completamente sintética de la bacteria Mycoplasma mycoides los, al trasplantarla en la cáscara vacía de otra bacteria.La última creación de Venter, que él ha llamado el Ave María Genoma, se hará a partir de cero con los genes que él y sus compañeros de instituto, Clyde Hutchison y Hamilton Smith, consideren indispensable para la vida.
El equipo está usando simulaciones por ordenador para entender mejor lo que se necesita para crear un simple, celular auto-replicante. «Una vez que tengamos un mínimo de chasis podemos añadir algo más», dice.
La búsqueda de Venter para diseñar algas que produzcan más aceite de lo normal también va bien. «Hemos sido capaces de aumentar la fotosíntesis tres veces, lo que significa que tenemos tres veces más energía por fotón [del sol] a partir de algas naturales», afirmó. También anunció que su programa para recorrer los océanos para buscar vida microscópica nueva hasta ahora ha encontrado 80 millones de nuevos genes para la biología.
Fuente: NewScientist
Foto: dfarber via photopin cc
![]()
Transmisión en tiempo real mediante Twitter de una cesárea
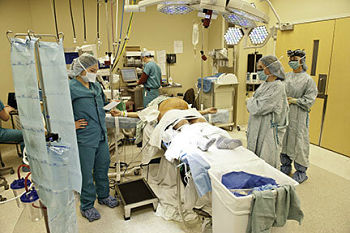
Actualmente casi prácticamente cualquier momento considerado importante se vive en directo a través de las redes sociales. Entonces, ¿por qué no hacer lo mismo con otros acontecimientos relevantes, como una operación de cesárea? Eso han pensado en un hospital de Texas, EE.UU., donde se han dedicado a contar, paso a paso y con imágenes, el desarrollo de esta intervención.
Los tweets comenzaron con los preparativos para la operación, y terminaron justo después de que el bebé hiciera su aparición. En Genbeta Social Media se puede ver la cronología de esta intervención. Las imágenes son bastante gráficas y no incluyen “censura” de ningún tipo. No es la primera vez que este centro hospitalario retransmite en directo una operación. En el pasado ya se atrevieron con un trasplante de corazón.
![]()

autobus las palmas aeropuerto cetona de frambuesa