Actualidad informática
Noticias y novedades sobre informática
La Curveball de 56 cubits de IBM puede afectar a los planes de computación cuántica de Google
 Justo cuando parecía subestimada, la computación clásica está volviendo a atacar. IBM ha ideado una manera de simular ordenadores cuánticos que tienen 56 bits cuánticos, o cubits, en un superordenador no cuántico – una tarea que antes se creía imposible. La hazaña mueve los palos de la portería en la lucha por la supremacía cuántica, el esfuerzo por superar a las computadoras clásicas usando las cuánticas.
Justo cuando parecía subestimada, la computación clásica está volviendo a atacar. IBM ha ideado una manera de simular ordenadores cuánticos que tienen 56 bits cuánticos, o cubits, en un superordenador no cuántico – una tarea que antes se creía imposible. La hazaña mueve los palos de la portería en la lucha por la supremacía cuántica, el esfuerzo por superar a las computadoras clásicas usando las cuánticas.
Antes se aceptaba ampliamente que un ordenador clásico no puede simular más de 49 qubits debido a limitaciones de memoria. La memoria necesaria para las simulaciones aumenta exponencialmente con cada cubit adicional.
Lo más cerca que se había llegado a poner a prueba el límite de 49 bits era una simulación de 45 bits en el Instituto Federal Suizo de Tecnología de Zúrich, que necesitaba 500 terabytes de memoria. La nueva simulación de IBM eleva la suposición al simular 56 qubits con sólo 4,5 terabytes.
La simulación se basa en un truco matemático que permite una representación numérica más compacta de los diferentes arreglos de qubits, conocidos como estados cuánticos.
Una operación de computación cuántica es típicamente representada por una tabla de números que indica lo que se debe hacer a cada cubit para producir un nuevo estado cuántico. En su lugar, los investigadores del Centro de Investigación T. J. Watson de IBM en Yorktown Heights, Nueva York, utilizaron tensores – tablas efectivamente multidimensionales aumentadas con ejes más allá de filas y columnas.
Gracias a los ejes adicionales, se puede introducir mucha más información en unos cuantos tensores, siempre y cuando sepamos escribirla en el lenguaje de los tensores. Los investigadores encontraron una forma de hacer precisamente eso para las operaciones de computación cuántica.
Vergonzosamente paralelos
Al escribir las operaciones en forma tensorial, también descubrieron una manera de dividir la tarea de simulación en lo que ellos llaman trozos «vergonzosamente paralelos», lo que les permitió usar los muchos procesadores de un supercomputador simultáneamente. Esto les ganó el último bit de eficiencia necesario para simular una computadora cuántica de 56 bits.
IBM se ha pasado de la raya «, dice Itay Hen de la Universidad del Sur de California. «Será mucho más difícil para la gente de dispositivos cuánticos exhibir supremacía.»
IBM tiene ahora un ordenador cuántico funcional de 56 bits que vive en su supercomputadora. Pero mientras que eso es una mejora con respecto al récord anterior, Andrew Childs en la Universidad de Maryland dice que no es un gran salto hacia adelante. No creo que estén afirmando que esto vaya a darles una simulación eficiente de sistemas cuánticos en un ordenador clásico «, dice.
Aun así, han subido la apuesta en la carrera por superar a los ordenadores clásicos con sistemas cuánticos. Google dijo anteriormente que estaban en camino de construir un procesador de 49 bits a finales de 2017, pero eso ya no les permitirá alcanzar la supremacía cuántica.
De hecho, Bob Wisnieff, el investigador principal del estudio de IBM, dice que su simulación actual funciona cerca de «mil millones de veces más lento» que las estimaciones teóricas para una computadora cuántica real de 56 cubits.
El equipo de Wisnieff planea experimentar con supercomputadoras cuyos procesadores pueden comunicarse eficazmente entre sí. Esperan poder exprimir unos cuantos más de estos canales de comunicación, lo que ayuda a acelerar el cálculo paralelo necesario para la simulación.
El objetivo de IBM es construir una computadora cuántica que pueda «explorar problemas prácticos» como la química cuántica, dice Wisnieff. Espera comprobar la precisión de las computadoras cuánticas frente a sus simulaciones antes de poner a prueba las computadoras cuánticas reales.
«Quiero ser capaz de escribir algoritmos para los que conozco las respuestas antes de ejecutarlos en una computadora cuántica real «, dice.
Referencia: arxiv.org/abs/1710.05867
![]()

¿Google está a punto de construir el primer qubit del mundo?

El qubit es la unidad básica de computación cuántica. Así que a los desarrolladores de hardware cuántico obviamente les gusta presumir de cuántos tienen. Aunque algunos afirman tener miles en sus dispositivos, hay un sentimiento muy real de que nadie ha construido ni siquiera uno solo.
Hay un par de cosas diferentes para las que usamos el nombre del qubit. Uno es un qubit físico. La parte física se refiere al hecho de que estos son objetos reales de la vida real. La parte de bits nos dice que estos objetos deberían tener dos posibles estados. Y lo que es para el cuántico, ya que necesitamos manipular los estados de una manera cuántica mecánica.
Cualquier qubit que merezca el nombre también debe tener un ruido extremadamente bajo. La forma en que los manipulamos e interactuamos debería ser casi perfecta. Como un logro de la física experimental, deben estar en la cúspide: Una maravilla de la ciencia y la ingeniería. Aun así, no son suficientemente buenos. Para las ordenadores cuánticos, casi perfecto es casi inútil.
Esto no es más de lo que esperamos de los ordenadores normales. Hay millones de píxeles en tu pantalla, pero te darías cuenta si sólo uno estuviera haciendo algo al azar. Lo mismo es cierto para todos los millones de bits que nadan alrededor en sus programas. Sólo se necesita un valor de conmutación de unos pocos porque están aburridos para que todo se convierta en un sinsentido.
Cuando programamos, a menudo olvidamos que los bits de nuestro ordenador tienen una forma corpórea real. Pensamos en ellos como un concepto abstracto, puro e incorruptible. De lo contrario, el desarrollo de software sería una actividad muy diferente. Los programas cuánticos están diseñados con el mismo grado de perfección en mente. Para ejecutarlos, necesitamos renuncias lógicas: encarnaciones de la idea misma de la información cuántica.
Construir qubits lógicos requiere que domemos la naturaleza de sus primos físicos. Necesitamos corrección de errores cuánticos. Muchas de las partes físicas son reunidas y conducidas a ser más grandes que la suma de sus partes. Cuanto más qubits físicos usemos, mejor será el efecto. El ruido disminuye exponencialmente, hasta que podemos estar seguros de que no ocurrirá ni un solo error durante el cálculo.
Esto no está exento de costes. No debemos pensar en gastar unos pocos cientos de qubits físicos para construir uno solo lógico. Pero si esto significa alcanzar la promesa completa de computación cuántica, valdrá la pena.
El diseño más popular para la corrección de errores cuánticos es el código de superficie. Para el código de superficie más pequeño, se necesitan 17 qubits físicos. Éstos construirían un qubit lógico, pero no con la suficiente complejidad como para hacer algo con él.
Todavía no se ha logrado nada parecido. Para ver por qué, echemos un vistazo a lo que se necesitaría.
Esto es un código de superficie. Los 17 puntos, tanto blancos como negros, son los qubits físicos. Las 24 líneas coloreadas representan un cierto tipo de operación cuántica, la controlada-NO. Para cada par de salidas conectadas, esta operación debería ser posible realizarla de forma limpia y directa.
El principal desafío es conectar todos estos controles-NO. Tener 17 qubits en nuestro procesador cuántico no es suficiente. También necesitamos el conjunto de instrucciones para soportar esta red específica de procesos.
Tener un montón de qubits físicos en una línea son noticias viejas, dos líneas al lado de la otra también es factible. Pero la red 2D de conexiones necesarias para el código de superficie es mucho más difícil.
Aun así, Google promete esto y mucho más para finales de año. Prometieron una red de 7×7 de 49 qubits físicos. Esto sería un gran paso adelante en comparación con otros dispositivos, como la celosía IBM 2×8 de 16 qubits físicos.
El dispositivo IBM tiene suficiente conectividad para hacer un bit lógico a partir de qubits físicos. En los próximos meses harán cosas mucho más geniales, como es de esperar del dispositivo a la vanguardia de su campo. Pero hacer un qubit lógico no será uno de sus logros.
El hecho de que los 49 qubits de Google serán tan revolucionarios hace difícil creer que lo veremos antes de que acabe el año. Los hitos más realistas para este año son un dispositivo de 17 qubit de IBM, y uno de 20 qubit de Google. Ambos tienen suficientes qubits para empezar con el código de superficie. Pero, ¿tienen el diseño correcto? Sólo el tiempo lo dirá.
Quizá no tengamos que esperar mucho tiempo. John Martinis, el encargado de construir los dispositivos cuánticos de Google, dará una charla la próxima semana. El título…
Escalado de errores lógicos de medición con el código de superficie
Los códigos de superficie están en el radar de los gigantes tecnológicos. El primer qubit lógico del mundo se acerca. ¿Ya lo ha gestionado el dispositivo de 20 qubit de Google?
Ampliar en: HACKERMOON
![]()
Block-chain en la cadena de suministros alimentarios
 IBM anunció hoy que está trabajando con un consorcio que incluye Dole, Golden State Foods, Kroger, McCormick y Company, Nestlé, Tyson Foods, Unilever y Walmart para llevar el beneficio de las cadenas de bloques (block-chains) a la cadena de suministro de alimentos.
IBM anunció hoy que está trabajando con un consorcio que incluye Dole, Golden State Foods, Kroger, McCormick y Company, Nestlé, Tyson Foods, Unilever y Walmart para llevar el beneficio de las cadenas de bloques (block-chains) a la cadena de suministro de alimentos.
IBM, al igual que la mayoría de sus competidores en el espacio de computación en la nube pública, ha estado trabajando en varios proyectos de cadenas de bloques en los últimos meses.
Dada la complejidad de la cadena de suministro de alimentos de productor a consumidor, block-chains podría encontrar un nicho muy interesante aquí porque permitiría más transparencia y trazabilidad (especialmente cuando las cosas van mal). La idea detrás de este proyecto y la colaboración entre estas diferentes empresas es averiguar dónde exactamente puede beneficiar el ecosistema de alimentos.
«La tecnología de Blockchain permite una nueva era de transparencia de extremo a extremo en el sistema alimentario mundial», escribe Frank Yiannas, vicepresidente de seguridad alimentaria de Walmart. «También permite a todos los participantes compartir información rápidamente y con confianza a través de una sólida red de confianza».
No es de sorprender que la Plataforma Blockchain de IBM constituya la base de gran parte de este trabajo. Soporta las tecnologías Hyperledger Fabric y Hyperledger Composer de Linux Foundation para la creación de aplicaciones basadas en cadenas de bloques.
Es interesante ver cómo una serie de grandes jugadores están trabajando para llevar block-chains a las empresas. A principios de este mes, por ejemplo, Microsoft lanzó un nuevo proyecto para hacer block-chains listos para la empresa, también, por ejemplo. A principios de este año, un estudio de IBM también encontró que un tercio de las empresas están buscando en cómo esta tecnología puede beneficiar a su negocio.
![]()
IBM logra fabricar las primeras neuronas artificiales con tecnología de cambio de fase
Durante décadas, la ciencia ha tratado de recrear la estructura del cerebro humano, pero hasta ahora era imposible imitar su potencia y densidad con los componentes disponibles. IBM acaba de dar un paso interesante hacia el cerebro positrónico imaginado por Asimov. Ha creado neuronas artificiales funcionales mediante tecnología de cambio de fase.
No es la primera vez que IBM anuncia un avance en esta tecnología de almacenamiento no volátil (los datos no desaparecen al apagar el dispositivo) basada en cristales que alteran su estructura molecular al recibir corriente eléctrica de diferente intensidad. Recientemente la compañía logró crear memoria de cambio de fase a un coste similar al de la RAM actual.
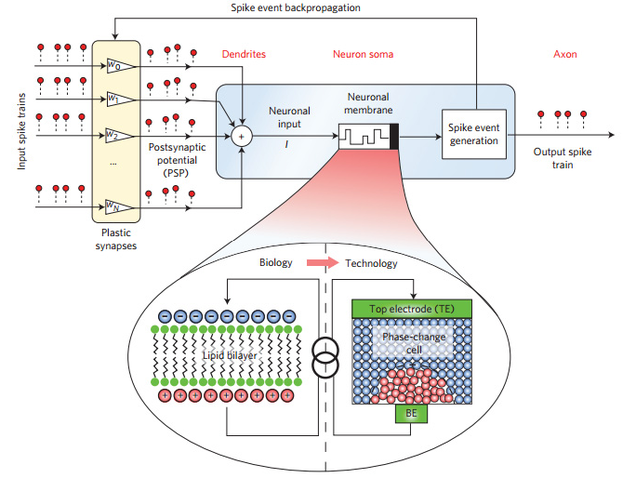
Esquema de las neuronas artificiales de cambio de fase. Foto: IBM
Sin embargo, este nuevo avance de IBM va mucho más allá de lograr que nuestro PC funcione con más agilidad. Lo que el equipo de investigadores que la compañía mantiene en Zurich ha logrado crear son neuronas que imitan perfectamente el funcionamiento de las neuronas humanas. En lugar de una membrana con enzimas, las neuronas artificiales unen el axon y las dendritas mediante un cristal de antimonio, germanio y telurio, un material similar al que se utiliza en los discos ópticos reescribibles.
Estas neuronas de cristal que cambia su estado se parecen mucho a su contrapartida biológica. Para empezar, su tamaño puede reducirse a unos pocos nanómetros, lo que permite agrupar la suficiente cantidad de estas neuronas en un espacio lo bastante reducido.
En la primera prueba, IBM ha puesto a funcionar 500 de estas neuronas en una hilera de cinco chips compuestos de 10×10 de estas neuronas, pero el sistema es escalable. Los investigadores explican en el estudio que han publicdo en Nature que se podrían crear chips viables para comercialización de 90 nanómetros ya mismo, y que en el futuro se podría reducir hasta 14 nanómetros.
… …
Artículo completo en: GIZMODO
![]()
Desempaquetado y encendido de un PC IBM PS/2 de 1990
Rick Chan dio con un PC IBM PS/2 Modelo 30 de ~1990, con procesador 286 a 10 MHz, 1MB de RAM y MS-DOS 5 y totalmente nuevo, sin desempaquetar desde que salió de la fábrica hace un cuarto de siglo.
Fuente: microsiervos
![]()
Gran impulso a ‘BigData’ y la computación cognitiva en el Reino Unido
Después del compromiso del Gobierno británico para ampliar el Centro Hartree en Daresbury en los próximos cinco años, IBM proporcionará el mayor apoyo al proyecto con un paquete de tecnología y conocimientos, valorados en 200 millones de libras esterlinas.
Continuar en: Blasting.News
El supercomputador Watson de IBM crea recetas de cocina

IBM creó ChefWatson, un programa que corre en el supercomputador, después de haber ingerido todos los datos de Bon Appétit, un sitio de recetas de cocina. Watson no utiliza las recetas en el sitio, en lugar de eso, clasifica todos los ingredientes por tipo de comida, estilo, lugar de origen, etc. Todo con el fin de hacer lazos entre los ingredientes y decidir cuáles se llevan bien entre ellos.
Fuente: conéctica
Licencia CC 4.0
![]()
IBM vuelve a ser la empresa que registró más patentes en 2014

El año pasado IBM inscribió 7534 patentes en la Oficina de Patentes y Marcas de EE.UU., una cifra que se ha situado bastante por encima de las de los últimos años. En 2013, la compañía obtuvo 6809 registros y en 2012 se quedó en 6478. El número supone que IBM ha obtenido 20 patentes al día.
Otras empresas se han mantenido en las mismas posiciones en la cabeza de carrera. Nada ha variado hasta el top 5. Samsung no ha aflojado su velocidad innovadora, sino todo lo contrario. Si en 2013 la coreana registraba 4676 patentes, el pasado ejercicio la cifra se elevó a 4952. Por detrás, se situaron Canon (4055), Sony (3224) y Microsoft (2829).
El ranking hasta el décimo puesto se completa con Toshiba (con 2608 patentes), Qualcomm (2590), Google (2566), LG Electronics (2122) y Panasonic (2095). En la posición número 11 aparece Apple. Por su parte, Huawei y Amazon han conseguido colarse entre los 50 primeros puestos, con la plaza número 48 y 50, respectivamente.
En total, en lo que ha durado este largo reinado de más de dos décadas, la empresa informática ha registrado 81500 patentes. En los doce meses la Oficina de Patentes registró 300678 patentes, así que puede decirse que el Gigante Azul ha aportado un 27% de la innovación en dicho organismo.
Fuente: ITespresso.es
![]()
Computación cognitiva en base a Big Data
Watson es sobre Big Data. Se trata de la absorción de grandes cantidades de información sobre temas específicos como – medicina, leyes, viajes, comercio minorista, metalurgia, petróleo y el gas, etc. lo que sea – permitiendo al usuario consultar los datos para buscar patrones que ayuden en el diagnóstico, ayuda a encontrar argumentos legales, tomar una decisión sobre dónde perforar para obtener petroleo, casi cualquier cosa.
Tomemos un ejemplo. Watson inicialmente está siendo probado como una ayuda a los médicos para hacer más rápidos y precisos los diagnósticos.¿Por qué la medicina?
1) Los investigadores médicos pueden leer como máximo unos pocos cientos de artículos médicos al año. Watson ha ingerido todos los 23 millones de artículos médicos en la Biblioteca Nacional de Medicina (MEDLINE).
2) Los errores médicos son ahora la tercera causa principal de muerte en los EE.UU., según IBM.
Watson está diseñado para interactuar con el historial médico del paciente, así como con los datos que el médico obtiene tras la anamnesis y exploración. Así que ante un paciente que llega con un diagnóstico difícil, el médico podría consultar Watson, que compararía los síntomas contra un vasto cuerpo de conocimiento médico para producir una serie de posibles diagnósticos.Esto es particularmente valioso cuando se trata de enfermedades raras en las que es probable que el médico tenga poco conocimiento de la enfermedad o sus síntomas.
Fragmento traducido de Three years after ‘Jeopardy,’ IBM gets serious about Watson por Bob Pisani de CNBC
![]()
20 años del primer smartphone

El 16 de agosto de 1994, IBM lanzó el Simon un dispositivo pionero que sentó las bases de una revolución de bolsillo: los smartphones. Aunque el término smartphone se acuñó mucho después, el IBM Simon está considerado el padre de los teléfonos inteligentes. Para celebrar su aniversario. Uno de estos terminales pasará a formar parte de la colección permanente del Museo de la Ciencia de Londres.
Aunque pesaba nada menos que medio kilo (510 gramos), el dispositivo ya era capaz de muchas de las funciones que hoy damos por normales en un smartphone: tenía aplicaciones, servía para tomar notas, y con él se podían enviar correos electrónicos. Su pantalla LCD monocroma de 4,5 pulgadas mostraba una resolución de 160 x 293 píxeles, y tenía funciones táctiles mediante un stylus.
El interior del Simon ocultaba un procesador de 16-bits a 16MHz, y compatible con ordenadores de arquitectura x86. La memoria RAM y el almacenamiento eran de 1MB respectivamente.
Este abuelo de los smartphones solo salió a la venta en Estados Unidos, donde se vendieron unas 50.000 unidades a un precio de 899 dólares. Todo un logro teniendo en cuenta que en aquel tiempo no existía conexión a internet en el móvil como la conocemos ahora, lo que limitaba el uso del Simon a casas u oficinas con línea fija.
Este comunicador personal también apuntaba maneras en cuanto a prácticas comerciales. Se discontinuó apenas un año después (febrero de 1995) y fue sustituido por el IBM Neon, una versión muy similar. El teléfono forma ya parte de la historia en la galería sobre la era de la información del popular Museo británico.
Fuente: GIZMODO
![]()

autobus las palmas aeropuerto cetona de frambuesa