Actualidad informática
Noticias y novedades sobre informática
Predicción del crimen gracias a «big data»

Las juntas de libertad condicional, en más de la mitad de los estados de Estados Unidos, usan predicciones basadas en el análisis de datos. En Los Ángeles usan el análisis de datos masivos para seleccionar las calles, grupos e individuos que tienen más probabilidades de verse involucrados en crímenes. Algo similar al programa Blue CRUSH (por las siglas Reducción el Crimen Utilizando el Historial Estadístico) que se emplea en la ciudad de Memphis, Tennessee.
En Richmond, Virginia, la policía correlaciona los datos sobre crímenes con la información de fechas de conciertos, acontecimientos deportivos, e incluso sobre cuándo pagan las nóminas a sus empleados las grandes compañías de la ciudad.
A medida que se incrementan los datos de que disponemos sobre los individuos y sus relaciones con los diferentes elementos del mundo, ya sea gracias a sus interacciones con su smartphone (GPS, etc.) o las huellas digitales dejadas a través de Internet, se podrán establecer correlaciones en base a datos masivos que nos dirán muchas cosas acerca de cuándo y cómo se producen los crímenes.
Ya hay un proyecto de investigación desarrollado bajo el amparo del Departamento de Seguridad Interior de Estados Unidos llamado FAST (Tecnología de Exploración de Futuros Atributos) que tratará de identificar a los potenciales terroristas monitorizando los indicadores vitales, el lenguaje corporal y otros patrones fisiológicos.
Viktor Mayer-Schönberger afirma en su libro Big Data:
Si las predicciones basadas en datos masivos fueran perfectas, si los algoritmos pudieran prever nuestro futuro con infalible claridad, no tendríamos elección para obrar en el futuro. Nos comportaríamos exactamente a tenor de lo predicho. De ser posibles las predicciones perfectas, quedaría negada la voluntad humana, nuestra capacidad de vivir libremente nuestras vidas. Y, además, no sin ironía, al privarnos de elección nos librarían de toda responsabilidad. Por supuesto, la predicción perfecta es imposible. Antes bien, el análisis de datos masivos lo que predecirá es que, para un individuo específico, hay cierta probabilidad de que tenga un comportamiento futuro determinado. Véase, por ejemplo, la investigación llevada a cabo por Richard Berk, profesor de estadística y criminología de la universidad de Pensilvania. (…) Berk sostiene que puede predecir un futuro asesino entre los presos en libertad condicional con una probabilidad de acierto mínima del 75 por 100. No está mal. Sin embargo, también significa que si los comités de libertad condicional se basan en el análisis de Berk, se equivocarán una de cada cuatro veces, y eso no es poco.
Una sociedad semejante sería más segura, pero también se destruiría la presunción de inocencia, el principio básico de nuestro sistema legal y de nuestro sentido de lo que es justo.
Los datos masivos son útiles para comprender el riesgo presente y futuro, y para ajustar nuestras acciones en consonancia. Sus predicciones ayudan a pacientes y aseguradoras, prestamistas y consumidores. Pero no nos dicen nada acerca de la causalidad. En cambio, asignar “culp” (culpabilidad individual) requiere que las personas a las que juzgamos hayan elegido actuar de determinada manera. Su decisión debe ser causa de la acción subsiguiente. Precisamente porque los datos masivos están basaos en correlaciones, constituyen una herramienta del todo inadecuada para juzgar la causalidad y asignar, pues, la culpabilidad individual.
Fuente: Xataka ciencia
Licencia CC
![]()

Chips maliciosos en planchas y teteras

Rusia y China han sido acusadas de espionaje internacional. Al contrario de la NSA, lo habrían hecho modificando diferentes objetos: teteras y planchas con chips maliciosos y memorias USB infectadas con un troyano.
Tal y como publicaba el periódico de San Petersburgo Rosbalt, se acusa a China de camuflar chips maliciosos en teteras y planchas, los cuales se conectarían a redes inalámbricas sin seguridad. Este tipo de chips (algunos con micrófono) se han encontrado en otras ocasiones en teléfonos móviles o en cámaras incluidas en vehículos.
Por si fuera poco, Estados Unidos recientemente acusó a Rusia de haber repartido una serie de memorias USB infectadas durante la cumbre del G20 celebrada en San Petersburgo. Este cruce de recriminaciones entre ambos países parece el típico juego de «…y tú más», acusándose unos a otros de las mismas prácticas.
Por su parte, el gobierno de Vladimir Putin, ha negado esta información y acusa a Estados Unidos de intentar «desviar la atención» sobre el escándalo destapado por Edward Snowden, el cual está actualmente refugiado en territorio ruso. Aunque este tipo de espionaje no es ninguna novedad, sigue arrojando leña al fuego y dando mayor perspectiva del mundo vigilado en el que vivimos. Planchar la ropa no creo que sea una actividad agradable, pero por lo menos no implique estar vigilado por gobiernos extranjeros.
Fuente: ALT1040
Licencia CC
![]()
Publicada ISO 27000:2013. Gestión de la seguridad en la información

Durante este mes de octubre BSI publicó la revisión del estándar internacional ISO/IEC-27001:2013, ya desde marzo de este año se habían publicado algunos borradores del nuevo estándar, a continuación vamos a enumerar algunos de los principales cambios incluidos en esta nueva versión.
Para comenzar, se realizaron cambios en su contenido, agregando y eliminando controles, reestructurando especialmente el Anexo “A” donde se aumenta a 14 los dominios de control y se reduce en 20 la cantidad de controles quedando en 113.
Esta nueva versión de ISO/IEC 27001:2013 se adapta con una serie de lineamientos que sirven para el desarrollo de un sistema de gestión de la seguridad de la información, que sin importar el tipo de empresa, se pueda alinear con otros sistemas de gestión en la empresa.
Ampliar en: Blog de Laboratorio
![]()
Entrevista a Shafrira Goldwasser, investigadora del MIT y Premio Turing

Shafrira Goldwasser (1958, EE.UU.) es profesora de Ingeniería Electrónica y Ciencia Computacional en el Massachusetts Institute of Technology (MIT), y profesora de ciencias matemáticas en el Weizmann Institute of Science, en Israel. Entre sus muchos logros en las ciencias computacionales destaca la construcción de los fundamentos teóricos de la criptografía moderna. Estos trabajos, juntos al desarrollo de nuevos métodos para comprobar la validez de pruebas matemáticas dentro de la teoría de la complejidad, le hicieron merecedora del Premio Turing en 2012.
Junto a otros premiados con este galardón, la Medalla Fields y los premios Abel y Nevanlinna, Shafrira Goldwasser, forma parte del primer Heidelberg Laureate Forum, que reúne durante una semana a 200 jóvenes investigadores con estos líderes científicos, con el objetivo de transferir el conocimiento y la experiencia entre diferentes generaciones. Es la única mujer de los 40 ‘laureados’.
¿Cuál cree que es el papel de las Ciencias de Computación Teórica frente al resto de las ciencias?
Las ciencias computacionales están presentes en casi todas las otras ciencias. Muchos de los problemas son problemas computacionales, a veces de manera evidente y otras no. Procesos del cambio climático, de la física, de la biología… pueden ser estudiados como problemas de computación. El cuerpo humano es una computadora, en la que se desarrollan procesos complejos. La ciencias de computación teóricas pueden ayudar a modelar lo que está sucediendo de manera apropiada, para saber cuán rápido avanzan los procesos, o cómo modificar los resultados.
Usted trabaja específicamente en criptografía, ¿cuales son los grandes retos de este campo?
En el pasado cuando hablábamos de encriptación hablábamos de privacidad: encriptación y desencriptación. Ahora estamos desarrollando la llamada criptografía funcional, que no desencripta todo el mensaje, solo ciertos trozos que responden a determinada búsqueda y mantiene en secreto el resto. Hay nuevos métodos que permiten operar sobre el mensaje encriptado, obtener el resultado que buscas, y con las claves solo desencriptar esta parte de la información.
¿Qué aplicaciones puede tener este nuevo método?
Por ejemplo en los sistemas de vigilancia. Ahora hay cámaras por todas partes, y la vigilancia, que es necesaria en un sentido, es también un problema porque puede atentar contra la privacidad de las personas. Una solución podría ser que toda la información registrada en las cámaras fuera encriptada. Cuando alguien, por alguna razón concreta, necesitara cierta información contenida en el registro, se podría hacer ese procesado manteniendo la encriptación, y tendrás el resultado encriptado. Podrías encontrar a un sospechoso sin recibir ninguna otra información. También en el correo encriptado: un tercero podría tener la capacidad de saber si un mensaje recibido encriptado es spam, pero nada más.
Cual cree que es la situación de la criptografía hoy, ¿podemos decir que se ha conseguido un protocolo 100% seguro?
El nivel de inviolabilidad de las técnicas más avanzadas es muy alto. Si alguien pudiera romper estos códigos en un tiempo alcanzable significaría que habría encontrado la respuesta a grandes problemas abiertos de las matemáticas, que los científicos, desde los tiempos de Gauss, no han sabido resolver. Siempre es posible, y podría ser que alguien lo resuelva de manera más rápida, pero hoy en día creemos que es imposible.
…
…
¿Qué importancia cree que tendrá la teoría cuántica en la criptografía en el futuro?
Creo que es una dirección muy interesante, ya que la seguridad basada en la teoría cuántica se basa en principios, que no pueden reducirse a problemas matemáticos, que potencialmente podrían ser resueltos. Pero en este momento todavía no lo veo posible porque el tipo de equipo necesario para transmitir y recibir señales cuánticas es muy sofisticado, y de hecho no existe todavía. Me cuesta imaginar cómo el mundo podría estar contactado de esta manera. Pero en términos teóricos es fascinante.
Entrevista completa en: sinc
![]()
Cookies sin cookies
Hay otra manera oscura de seguimiento de los usuarios sin necesidad de utilizar cookies o incluso Javascript. Ya ha sido utilizado por numerosos sitios web, pero pocas personas saben de él.
Este método de seguimiento trabaja sin necesidad de utilizar:
Cookies
Javascript
LocalStorage / sessionStorage / globalStorage
Flash, Java y otros plugins
Su dirección IP o la cadena de agente de usuario
Los métodos empleados por Panopticlick.
En su lugar utiliza otro tipo de almacenamiento que es persistente entre reinicios del navegador: el almacenamiento en caché.
Incluso cuando se han desactivado las cookies por completo, tiene Javascript desactivado y se usa un servicio VPN, esta técnica todavía será capaz de seguirte.
Entonces, ¿cómo funciona esto? Esta es una visión general:
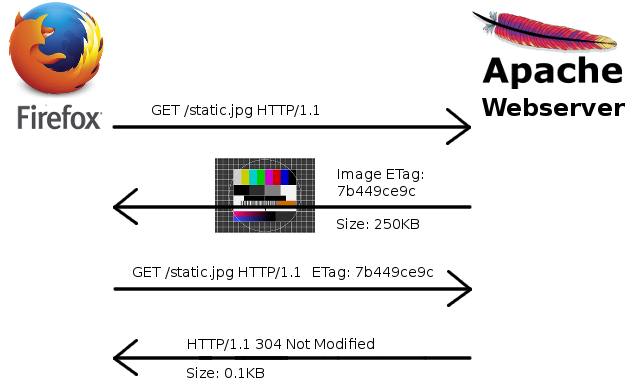
El ETag que se muestra en la imagen es una especie de suma de comprobación (cheksum). Cuando hay cambios de imagen, el cheksum varía. Así que cuando el navegador tiene la imagen y conoce a la suma de comprobación, puede enviarla al servidor web para su verificación. El servidor web comprueba si la imagen ha cambiado, en caso negativo, la imagen no necesita ser retransmitida y se ahorra la transmisión de datos.
Los lectores atentos pueden haber notado ya cómo se puede usar esto para rastrear a las personas: el navegador envía la información al servidor que recibió anteriormente (la ETag). Eso suena muy parecido a los cookies, ¿no? El servidor puede simplemente dar a cada navegador un ETag único, y cuando se conecte de nuevo, puede buscarlo en su base de datos.
¿Qué podemos hacer para evitarlo?
Una cosa que no te recomiendo que lo hagas cada vez que visitas una página en la que desea un poco más de seguridad, abre una ventana de navegación privada y el uso de https exclusivamente. Hacer esto elimina por sí solo los ataques como INCUMPLIMIENTO (el último truco https), desactiva cualquier y todos los cookies de seguimiento que puedas tener, y también elimina la caché de seguimiento. Por ejemplo se puede usar este modo de navegación privada cuando se acceda a un banco en línea.
Además de eso, depende del nivel de paranoia
Actualmente tengo una respuesta clara, el seguimiento de caché es prácticamente indetectable, sino también porque el almacenamiento en caché en sí es útil y salva a las personas tiempo y dinero. Los alojamientos de sitios web consumen menos ancho de banda (y si se piensa en ello, en que los usuarios finales son los que tendrán que pagar la factura), las páginas se cargan más rápido, y sobre todo en los dispositivos móviles que hace una gran diferencia si no tienes un plan ilimitado 4G. Es aún peor cuando se tiene una conexión de alta latencia y bajo ancho de banda por ejemplo si se vive en una zona rural.
Si eres muy paranoico, lo mejor es simplemente deshabilitar el almacenamiento en caché por completo. Esto evitará cualquier seguimiento, pero yo personalmente no creo que merezca la pena.
La extensión de Firefox «autodestrucción de cookies» tiene la posibilidad de vaciar la caché cuando no se está usando el navegador por un tiempo. Esto podría ser una alternativa aceptable deshabilitar el almacenamiento en caché, sólo puede ser rastreado durante la visita, y ya se puede hacer eso de todos modos, siguiendo las páginas que fueron visitadas por la dirección IP, por lo que no es gran cosa. Las visitas posteriores aparecerán como parte de un usuario diferente, asumiendo que todos los otros métodos de seguimiento ya se han evitado.
No estoy al tanto de cualquier complemento que elimine periódicamente la caché (por ejemplo, una vez cada 72 horas). Esta sería otra buena alternativa para el 99% de los usuarios, ya que tiene un impacto relativamente bajo sobre el rendimiento, mientras que permite limitación de las capacidades de seguimiento.
Fuente (con demostración): LUVB1E
![]()
Toshiba desarrolla nueva criptografía cuántica a prueba de la NSA
El nuevo sistema de criptografía cuántica que desarrolla Toshiba ofrece privacidad absoluta, según aseguran, a prueba espionajes y curiosos. Durante los últimos meses cuando hablamos de seguridad en la red, inmediatamente pensamos en la NSA y por supuesto en su programa de vigilancia PRISM. Y es que desde que Edward Snowden revelara toda la información acerca del espionaje que las agencias de inteligencia estadounidenses mantienen con, prácticamente, casi todo el mundo, muchos nos cuestionamos las medidas de seguridad que tomamos en nuestros dispositivos, y un buen sistema de criptografía puede ser una buena forma de aislar a los ojos curiosos de nuestros datos privados.
Toshiba asegura estar trabajando en un nuevo sistema de criptografía cuántica, según aseguran, que servirá para proteger los datos e información de cualquier persona, desde un agente secreto de una oficina de inteligencia, un presidente de algún país (para evitar nuevos casos como el espionaje al presidente de México), o cualquier persona que desee privacidad absoluta de sus datos. ¿Acaso alguien no la desea? Una tecnología prometedora, pero aún en pleno desarrolloEl principal problema, por así decirlo, de las soluciones de seguridad a base de sistemas de criptografía cuántica, es que su desarrollo está aún muy verde, por así decirlo, este tipo de criptografía tiene aún un largo camino por recorrer antes de ser una solución viable (¿comercial?) para todas las personas.
Eso sí, cuando esté lista, podría realmente ser impenetrable, al menos en teoría. La criptografía cuántica, como su nombre lo indica, hace uso de la física cuántica para prometer que la información enviada desde un punto “A” llegue a un punto “B” sin posibilidad de ser interceptada, ni siquiera por la NSA, MI-6, KGB, o cualquier agente secreto de película, o agente externo. La teoría indica que nadie puede interceptar o intentar modificar un sistema cuántico sin perturbarlo, lo que dejaría evidencia clara de la filtración, o quizás destruiría la información en el proceso, algo que es parte de los propósitos de los investigadores de Toshiba.
Esta investigación es bastante costosa, por lo que ciertamente tendremos que esperar un buen tiempo antes de verla como una realidad. Aún así, promete ser una solución realmente segura para la privacidad. Como menciona Andrew Shields, director del grupo de información cuántica en los cuarteles europeos de investigación de Toshiba: Este tipo de sistemas sencillamente no pueden ser derrotados por ningún tipo de avance en la computación, ni nigún algoritmo matemático o ingeniería complicada. Las leyes de la física no pueden romperse, y esto es lo que ofrece completa seguridad. Si bien ya hay empresas que ya ofrecen sistemas de seguridad relacionados en parte a la física cuántica, son extremadamente costosos. Lo que desea Toshiba es ofrecer este protocolo a todo mundo, y esperemos que lo logre muy pronto.
Fuente: ALT1040
Licencia CC
![]()

Test Público Completamente Automatizado para Diferenciar a los Seres Humanos de las Computadoras, Captcha
Las siglas inglesas de Completely Automated Public Turing Test to Tell Computer and Human Apart (Test Público Completamente Automatizado para Diferenciar a los Seres Humanos de las Computadoras) quizá os suenen más si las resumimos en el término más familiar Captcha.
Pero ¿qué utilidad tienen realmente estas palabras que aparecen en muchos sitios de Internet y quedebemos reproducir con nuestro teclado, en ocasiones forzando al máximo nuestra capacidad de lectura? (en mi caso, muchas veces me equivoco, lo cual me debe emparentar más con una computadora que con un humano).
Los Captcha llegaron para controlar el caos de spam generado en la década de 1990 en el ámbito de Internet. Los spambots inundaban los buzones de entrada del correo electrónico, y jalonaban los foros online. Pero todo esto cambió en el año 2000 gracias a un joven de 22 años.
Luis von Ahn, recien licenciado en la universidad, tuvo una idea para acabar con el spam: obligar a los que se inscribieran a probar que eran seres humanos y no un maldito bot. Así que buscó algo que resulta fácil para los seres humanos, pero no tanto a las máquinas: reconocer letras.
Se le ocurrió entonces presentar letras garabateadas y difíciles de leer durante el proceso de registro,y dejar solo unos segundos para descifrarlas y reproducirlas. Cuando Yahoo implementó este sistema, redujo los spambots de forma considerable en solo 24 horas.
A raíz del desarrollo de los Captcha, Von Ahn obtuvo un puesto como profesor de informática en la universidad Carnegie Mellon, así como contribuyó a que recibiera uno de los prestigiosos premios “genio” de la fundación MacArthur, dotado con medio millón de dólares. Sin embargo, algo fallaba aún.
El mayor error de los Captcha pasaba por exigir a los usuarios un montón de esfuerzo y tiempo colectivo para nada, o simplemente para evitar el spam. Un tiempo y un esfuerzo computacional humano que Von Ahn trató de darle utilizar inventando un sucesor de Captcha: ReCaptcha.
Con este nuevo sistema, la gente ya no teclea letras aleatorias, sino que teclea dos palabras procedentes de proyectos de escaneo de textos que el programa de reconocimiento óptico de caracteres de un ordenador no podría entender. La primera palabra sirve para confirmar lo que han introducido otros usuarios, y es que, por consiguiente, una señal de que el usuario es humano. La otra palabra es una palabra nueva que precisa de desambiguación.
Para garantizar que el sistema es efectivo, el sistema presenta la misma palabra borrosa a una media de 5 personas diferentes que la deben insertar correctamente antes de aceptarse como válida. Lo que ahorra mucho tiempo y dinero, tal y como explican Viktor Mayer-Schonberger y Kenneth Cukieen Big Data:
Con aproximadamente diez segundos por uso, 200 millones de ReCaptchas diarios ascienden a medio millón de horas diarias. El salario mínimo en Estados Unidos era de 7,25 dólares brutos por hora en 2012. Si uno tuviera que dirigirse al mercado para desambiguar las palabras que un ordenador no había conseguid descifrar, costaría alrededor de cuatro millones de dólares diarios, o más de mil millones de dólares al año.
Esta clase de trabajo colaborativo basado en el ingente número de datos que dejamos por nuestro paso por la Red es indudablemente la forma en la que muchos proyectos del presente y del futuro próximo están prosperando para mejorar nuestra calidad de vida o para afrontar problemas que de otro modo serían irresolubles. Como la web donde te predicen si tu vuelo se retrasará o se cancelará.
Fuente: Xataka CIENCIA
Licencia CC
![]()
Las mayores perdidas de datos de la historia de la informática
1 – Heartland Payment Systems. 2008. Hackeo. Pagó 60 millones de dólares a Visa para hacer frente a las pérdidas de los titulares de tarjetas de crédito y débito afectadas por el robo de datos que Heartland sufrió en 2008. La violación fue revelada por Heartland en enero de 2009 y se cree que afectó a más de 100 millones de números de tarjetas de crédito y débito.
2 – TJ Maxx y Marshalls. 2007. Hackeo. Un hacker o hackers robaron datos de al menos 45,7 millones de tarjetas de crédito y débito de los compradores en las tiendas a precios de descuento como TJ Maxx y Marshalls en un caso cree que es el más grande tal violación de información al consumidor.
3 – American Online. 2005. Robo. Un ex ingeniero de software de American Online robo de 92 millones de nombres de usuario y direcciones de correo electrónico para venderlos a los spammers. Y a esto hay que unir que en 2006, de nuevo, AOL, no se sabe por qué, dejo en abierto dtos de búsquedas, 20 millones de “queries”.
4 – Sony PlayStation Network. 2011. Hackeo. Un hackeo que afectó a 77 millones los clientes. Un coste de 170 millones de dólares.
5 – 70 Millones, el ejercito de EEUU. 2009. Imprudencia. Por un disco duro defectuoso que envió al proveedor para su reparación sin destruir primero los datos.
David McCandless de Information is Beautiful ha creado una impresionante gráfica, que ilustra el tamaño relativo de las pérdidas de datos famosos:
http://www.informationisbeautiful.net/visualizations/worlds-biggest-data-breaches-hacks/.
Fuente: javiergarzas.com
![]()


autobus las palmas aeropuerto cetona de frambuesa