La web de Maco048. Criminología
Las mentes simples casi siempre yerran en sus juicios
CrispCas9 para editar el genoma
La técnica de Crisp Cas9 descubierta solo hace un par de años ha revolucionado la ingeniería genética y la posibilidad de crear animales transgénicos, así como crear mutaciones en animales de laboratorio que sean modelos para estudio de enfermedades hereditarias, tanto las producidas por mutaciones simples, como las que se originan por varias mutaciones en disitnos genes, en diferentes cromosomas o sitios del genoma. Por ende podría ser utilizada para terapia génica en humanos que padecen enfermedades hereditarias.
![]()

Huella genética y crímenes
Nuestros ADN son, en general bastante coincidentes, pero hay una serie de regiones tales que la probabilidad de que dos personas no emparentadas muestren la misma pauta de variación son prácticamente nulas. Así que si se comparan cuatro o cinco de estas regiones tenemos un método de identificación tan bueno como las huellas digitales, pero con la ventaja que sólo hace falta un pelo, una gota de sangre o de semen, etc.
El primer resultado práctico de esta técnica sirvió para condenar a Colin Pitchfork, quien había violado y asesinado a dos niñas de 15 años en 1983 y 1986. El principal sospechoso era un joven que había admitido el asesinato de la segunda, pero no de la primera, siendo ambos modus operandi muy similares.
Jeffreys comparó el ADN de muestras de semen de ambos casos y concluyó que el hombre que había sido el culpable de aquellos crímenes era el mismo, pero no era el joven acusado. La policía pidió a los vecinos de las proximidades que proporcionaran muestras de sangre o saliva para ver si coincidía. No se encontró ninguna coincidencia. Aunque consiguieron el 98% de partición parecía que había fallado.
No obstante, oyeron a una persona jactándose de que había cobrado 200 libras por haber donado una muestra haciéndose pasar por su amigo Colin Pitchfork, un panadero de la localidad. La policía lo detuvo en 1987 y las muestras de ADN del semen coincidieron con su ADN, así que el juez confió más en esta prueba que en la palabra del anterior joven, a quien se le declaró inocente.
Casos antiguos que se resolvieron
La ventaja de la huella genética es que permite conseguir información de casos que sucedieron en el pasado. Por ejemplo, en 2006 hubo una pelea en un pub en Surrey, en el sur de Inglaterra. La policía tomó muestras de las diferentes personas presentes aquella noche en el pub, incluido el chef Mark Dixie. Cuando introdujeron su huella genética en la base de datos nacional se encontró que coincidía exactamente con la de un sospechoso de asesinato cometido en Londres nueve meses atrás.
Pero hay casos todavía más espectaculares porque se dieron antes de que se descubriera la huella genética, como el caso de Christoher Smith. Había sido arrestado en 2008 por conducir bebido y se le extrajo una muestra de ADN. Aunque murió poco después por una enfermedad terminal, posteriormente se desubrió que había cometido un asesinato 35 años atrás. La policía descubrió posteriormente pruebas adicionales que lo inculpaban y el fiscal declaró que si hubiera estado vivo lo hubieran inculpado por aquel asesinato.
Y más curioso todavía: te pueden encontrar por un familiar. En el año 2003, Micky Little resultó muerto cuando alguien lanzó un ladrillo al pasar con su camión debajo de un puente. La entrada del mismo a través de la ventana le causó un ataque al corazón. La policía encontró restos de ADN en el ladrillo y una muestra del mismo ADN se encontró en un coche que había sido abandonado en un lugar cercano al de los hechos.
La persona que había lanzado el ladrillo no tenía antecedentes, por lo que su ADN no estaba en la base de datos, pero sí se encontró una coincidencia parcial. Era muy probable que el culpable fuera un miembro de la familia del que estaban buscando. La presencia del cromosoma Y les dio unas ciertas características, como que era muy probable que fuera blanco y, por otras razones, que tuviera menos de 35 años y viviera cerca del lugar. Cuando reunieron todas estas pruebas apuntaron a Craig Harman, dependiente de una tienda. Como sospechoso, se le extrajo una muestra de sangre y en el juicio se le declaró culpable de homicidio y sentenciado a 6 años de prisión. Fue la primera vez que se encontró un culpable por las pruebas de ADN de un familiar.
Hay otro caso similar. Hacía tiempo, la policía había perdido la esperanza de resolver una violación que había tenido lugar en 1990. No había ningún sospechoso. El año 2004 se reexaminaron las muestras forenses del caso con los últimos métodos del ADN y se consiguió la huella genética del agresor. Desgraciadamente, no coincidía con ninguna de la base de datos nacional. Dos años después, la hija de un tal Keith Davidson fue amonestada por una agresión y se le extrajo una muestra de ADN. Resultó que coincidía parcialmente con la del caso de 1990. Una muestra genética extraída del propio Davidson padre confirmó que era culpable. Fue sentenciado a 8 meses de prisión.
Artículo completo en: XATAKA CIENCIA
Licencia Creative Commons
![]()
Cómo somos de parecidos a ciertos animales según nuestros ADN

Gráfica de barras en la que se indica en qué porcentaje los seres humanos somos parecidos a otros animales.
Nuestro «primo» más cercano es como cabría esperar el chimpancé (90%), pero resulta que somos más parecidos a un ratón (88%) que a un perro (84%) e incluso –agárrate– a los ornitorrincos (69%) que a los pollos (65%).
Fuente: Jishai
![]()
La historia científica detrás del encuentro del nieto que emociona a Argentina

Él, el nieto 114, tras todos estos años, pudo finalmente encontrarse con Estela Carlotto, la presidenta de Abuelas de Plaza de Mayo, en un encuentro privado que fue celebrado en público.
Una parte importante y crucial de la historia que conmueve a Argentina en estos días tiene que ver con la ciencia que lleva años dedicada a identificar a los restos de desaparecidos durante el régimen militar argentino (1976-1983) y a los hijos de desaparecidos que fueron apropiados.
Como parte de un procedimiento que la Comisión Nacional por el Derecho a la Identidad (CONADI) y las Abuelas de Plaza de Mayo han perfeccionado con los años, Ignacio Hurban se acercó voluntariamente en junio pasado porque tenía dudas sobre su identidad y se prestó al análisis genético en el Banco Nacional de Datos Genéticos (BNDG) que acaba de confirmar su parentesco y su nombre: Guido Montoya Carlotto.
El Banco custodia las muestras genéticas que aportaron 310 familias que buscan a nietos robados durante el régimen militar, y con ellas se contrastó el ADN de Guido.
Penchaszadeh participó en los años 80 en la creación del llamado «índice de abuelidad», una fórmula auspiciada por Abuelas y que sirve para identificar personas a partir del ADN de sus abuelos.
El primer resultado de este índice fue en 1984, con la restitución de Paula Eva Logares. Pero aunque con Guido ya suman 114 los nietos recuperados, aún falta encontrar a alrededor de 400 más.
Se calcula que por lo menos 500 mujeres estaban embarazadas en el momento de su desaparición forzosa, o sea que debe haber otros tantos niños nacidos en centros clandestinos de detención.
«Lo más difícil ha sido siempre la localización de un caso», explica a BBC Mundo Penchaszadeh.
«El análisis genético es lo más simple, hoy en día. Hace treinta años era más complicado porque el ADN no se podía analizar de forma directa, no había la tecnología adecuada. Pero en los 90 el análisis pasó a ser muy común en muchos ámbitos»
Ampliar en: BBC MUNDO

![]()
La sangre del rey Luis XVI no estaba en la calabaza

Científicos españoles ponen fin al enigma de la sangre del rey Luis XVI supuestamente contenida en el interior de una calabaza y recogida tras su decapitación durante la Revolución Francesa. El análisis del genoma completo a partir de las muestras de sangre indica que el propietario no era el Borbónsino un individuo con rasgos muy diferentes.
La historia de la calabaza y la sangre de Luis XVI daría para una novela de ambiente histórico. A mediados de 2009, un colega italiano contacta con el científico español Carles Lalueza-Fox, del Instituto de Biología Evolutiva, en Barcelona, con un extraño encargo. Dos hermanos italianos, miembros de la alta sociedad de Bolonia, se han puesto en contacto con él para comprobar si la reliquia de la que son poseedores – custodiada en secreto en la cámara acorazada de un banco – es auténtica.
La reliquia es una calabaza ricamente adornada mediante técnica pirográfica, que lleva en posesión de una familia de Bolonia desde hace más de un siglo. Sus propietarios estiman que vale más de dos millones de euros y su verdadero valor está en su contenido: un pañuelo supuestamente impregnado con la sangre del rey Luis XVI, recogida a los pies de la guillotina donde fue ejecutado el 21 de enero de 1793. En el exterior de la calabaza aparecen retratados varios protagonistas de la revolución francesa, como Danton o Robespierre, y en una inscripción se explica que Maximilien Bourdaloue, testigo de la ejecución, mojó su pañuelo en la sangre del rey, lo metió en la calabaza y ordenó a un artista parisino su decoración.
En aquel momento no tenían muestras genéticas de miembros de la familia de Luis XVI con quien comparar, pero en 2013 un equipo francés y belga pidió muestras a tres borbones actuales de dos ramas de la familia distintas y comprobaron ya que que el cromosoma Y no coincidía con el hallado por los científicos del CSIC en la calabaza. «Para clarificar el asunto», explica Lalueza-Fox, «nos dijimos: hagamos el genoma completo y miremos más cosas». Y eso es precisamente lo que hicieron y los resultados que publican en la revista Scientific Reports.
«Hemos hecho un análisis funcional global del genoma«, nos cuenta el investigador, «que consiste en mirar rasgos externos de la persona, características físicas, la susceptibilidad a enfermedades… y hemos llegado a la conclusión de que probablemente no es Luis XVI el que está dentro de la calabaza». Además de comprobar que los rasgos genéticos generales difieren, Lalueza-Fox ha encontrado discrepancias físicas que descartan que el propietario de la sangre de la calabaza fuera el rey. «Hemos buscado rasgos que según las crónicas o los testigos tuviera el rey», apunta, «y había dos muy remarcables: uno era la estatura, todos decían que era el hombre más alto de la corte, variantes genéticas y nuestros datos indican que el propietario de la sangre era un individuo el promedio de estatura de la época, bastante bajo«.
Ampliar en: Néxt
![]()
Identifican mediante ADN el lugar de origen de una persona

Desde hace unos años, los científicos utilizan estas sutiles diferencias genéticas para estudiar las migraciones de los humanos de un continente a otro, desde la salida de África hasta la colonización de Asia y Europa. Estas pistas, por ejemplo, han permitido determinar el origen asiático de las poblaciones amerindias, llegadas desde el norte a través del estrecho de Bering durante las grandes glaciaciones o el origen de algunas poblaciones que viven en mitad del Pacífico. Sin embargo, cuando se trataba de determinar el origen de un individuo contemporáneo particular, los resultados eran bastante pobres y se aproximaban con un error de hasta 700 km a la zona correcta.
Un equipo coordinado por Eran Elhaik, de la Universidad de Sheffield, acaba de presentar el primer sistema que permite determinar el origen de un individuo a escala global concreto con una tasa de acierto del 83%. En un juego de palabras, los científicos han bautizado como Geographical Population Structure (GPS) al algoritmo desarrollado a partir de los datos genéticos proporcionados por miles de individuos de todo el mundo al proyecto Genographic y del programa 1000 Genomas.
El sistema nace de combinar diferentes variables genéticas y geográficas para diseñar el algoritmo predictivo, que presentan esta semana en Nature Communications. «Lo aplicamos a unos 600 individuos de todo el mundo«, escriben los investigadores, «e incluimos a poblaciones altamente heterogéneas de Kuwait, Puerto Rico y Bermudas, así como a comunidades del mismo país, como peruanos de Lima e indígenas de las zonas andinas». A continuación, pusieron a prueba su sistema de predicción y comprobaron que su GPS genético era capaz de identificar el origen de un 83% de los individuos.
Referencia: Geographic population structure analysis of worldwide human populations infers their biogeographical origins (Nature Communications).
Ampliar en: nèxt
![]()
Las bacterias que descomponen los cadáveres pueden cambiar con el tiempo

El tipo de bacterias implicadas en la descomposición humana puede cambiar con el tiempo, según un nuevo estudio publicado este miércoles en la revista ‘Plos One’ por Aaron Lynne y sus colegas en la Universidad Estatal Sam Houston y el ‘Baylor College of Medicine’, ambas instituciones en Texas, Estados Unidos.
Las bacterias pueden tener cierta influencia para impulsar el proceso natural de descomposición humana, pero se sabe poco acerca de la diversidad de especies bacterianas involucradas. Estudios anteriores se han limitado al enfoque tradicional de cultivo de bacterias, mientras que la gran mayoría de las bacterias que residen en el cuerpo humano en realidad no pueden cultivarse experimentalmente.
Para ayudar a resolver este problema, los autores estudiaron la descomposición de dos cadáveres humanos en condiciones naturales usando un método de secuenciación de genes para analizar el ADN bacteriano, en lugar de depender de los métodos de cultivo tradicionales. Este sistema de secuenciación les permitió medir genes bacterianos presentes en cualquier región del cadáver, ofreciéndoles un mapeo de toda una comunidad microbiana en dos momentos diferentes.
Encontraron que estas comunidades bacterianas fueron diferentes entre los dos cuerpos y entre las regiones de un mismo cuerpo y que cambiaron con el transcurso del tiempo. Los autores sugieren que las comunidades bacterianas pueden seguir patrones específicos de cambio. Este enfoque de secuenciación de genes puede ser una herramienta valiosa para la disección aún más el papel de las bacterias en la descomposición humana.
«Este estudio es el primero en catalogar bacterias presentes internamente en el inicio y la etapa final, desde la hinchazón a la descomposición humana. En última instancia, esperamos llegar a un sistema que permita ver la descomposición de una manera que pueda ayudar a los modelos forenses a determinar el intervalo post-mortem», subrayó Lynne.
![]()
Cinco genes que definen el ancho de la cara

Se trata de un avance que puede hacer a los policías sonreir de oreja a oreja: investigadores han identificado cinco genes que ayudan a controlar el ancho de la cara humana. A pesar de que cientos de genes implicados en la forma de la cara aún no se han identificado, los resultados representan un primer paso hacia la reconstrucción facial con el ADN.
Los laboratorios de criminalística ven un futuro brillante para la genómica forense, que ya está avanzando hacia la predicción de cabello y color de ojos con base en la información genética. Pero el objetivo final es reconstruir el rostro completo de un criminal a partir de su ADN, que puede ser encontrado en la escena del crimen.
Pero la cara es una estructura muy compleja, que requiere mucho aporte genético. Hace ocho años, Manfred Kayser, genetista de la Erasmus MC en Rotterdam, Países Bajos, se preguntó si no sería ni siquiera posible desentrañar las versiones de un gen que daría lugar a una nariz ancha y una frente ancha. Si lo fuera, él razonó, entonces, finalmente, un programa de computadora podría construir un compuesto de la cara de un autor sobre la base de ADN, tanto como un dibujante de hoy combina los recuerdos de testigos para ayudar a una investigación. «Si usted puede conseguir en la forma de la nariz, los ojos, los labios, pueden ser de mucho valor», dice Bruce Budowle, genetista de la Universidad North Texas Health Science Cente en Fort Worth, que no participó en el trabajo.
Antes de Kayser y sus colegas pudieran comenzar a identificar los genes, tenían que romper la cara en características discretas medibles que puedan ser evaluadas en cada individuo. En cuanto a las imágenes de resonancia magnética, se escogieron nueve puntos de referencia en la cara. Las distancias entre diferentes pares de puntos de referencia en una cara dada eran rasgos para el equipo para evaluar, por ejemplo, la separación entre los ojos o la distancia desde la punta de la nariz a su base.
Como parte de International Visible Trait Genetics Consortium, él y sus colegas examinaron el ADN de cinco grupos de personas para ver si las variantes específicas de un gen se asocian con cada rasgo. Cada grupo contiene entre 545 y 2470 personas. Otros tres grupos de personas fueron posteriormente evaluados, como una manera de probar de forma independiente las correlaciones genéticas derivadas de los primeros cinco grupos.
Cinco genes surgieron como importantes para los rasgos faciales, Kayser y sus colegas lo publican en PLoS Genetics. Los genes influenciando rasgos tales como la anchura de la cara, la distancia entre los ojos, y en qué medida la nariz sobresale. Un gen, denominado PAX3, ya había sido relacionado con la forma de la cara de los niños. Otros investigadores habían vinculado previamente dos de los otros genes, uno en el cromosoma 2 y otro en el cromosoma 3, con los problemas faciales como labio leporino o mandíbulas deformes. Los dos genes finales fueron nuevamente conectados con el desarrollo facial, señala.
En el lado negativo, el trabajo confirma lo que muchos habían sospechado. «No hay variantes comunes con grandes efectos», dice Lavinia Paternoster, genetista de la Universidad de Bristol en el Reino Unido, que planea trabajar con Kayser en el futuro en la búsqueda de más genes . «Es probable que existan muchos cientos o miles de estas variantes,» que tienen cada una una pequeña influencia sobre la cara, se dice.
Que muchos más genes estén involucrados, aportando cada uno un poco más hacia la construcción de la cara, significa que «esto es sólo el primer paso en un largo camino», dice Budowle. El equipo de Kayser planea detectar otros genes, aumentando el número de puntos de referencia que evaluar y adquirir imágenes de resonancia magnética de más personas. La búsqueda de genes con efectos pequeños requiere que se estudie un montón de gente, y eso podría ser difícil de hacer, ya que no hay muchos estudios en los que se recogiera el ADN y se realizaran resonancias magnéticas.
Budowle es optimista de que dentro de dos a cinco años, alguna forma de reconstrucción facial con el ADN será posible. Pero eso ciertamente no es posible ahora, Paternoster dice: «La variabilidad en este estudio sólo explica una muy pequeña proporción de la variabilidad en la forma de la cara, y así no se puede utilizar para predecir la forma de la cara.»
Fuente: Science AAAS
![]()
¿Golpe fatal contra ENCODE y la “utilidad” del ADN “basura”?

Una de las grandes noticias científicas de 2012 fue la publicación de los resultados del proyecto ENCODE (ENCyclopedia Of DNA Elements), que reclamaban una “función” bioquímica para gran parte del mal llamado ADN basura (“junk ADN” que no “garbage ADN”). Este resultado requería una revisión de ciertos aspectos de la teoría evolutiva y la genética, por lo que causó un gran enfrentamiento entre los expertos. Se han escritos muchos artículos en contra de la posible “función” del ADN basura, pero el definitivo es Dan Graur et al, “On the immortality of television sets: “function” in the human genome according to the evolution-free gospel of ENCODE,” Genome Biology and Evolution, AOP February 20, 2013 [copia gratis]. Me he enterado vía Robin McKie, “Scientists attacked over claim that ‘junk DNA’ is vital to life. Rivals accuse team of knowing nothing about evolutionary biology,” The Guardian, 24 Feb 2013, por lo que he buscado con urgencia a PaleoFreak (gran crítico de ENCODE en Twitter) y me he encontrado con un aplastante y demoledor “Golpe final al ENCODE (y viva el ADN basura),” 21 Febrero, 2013. Recomiendo su lectura, “no exenta de ironía y cierta crueldad.”
Ampliar en: Francis (th)E mule Science’s News
![]()
Algunas cifras curiosas del ADN
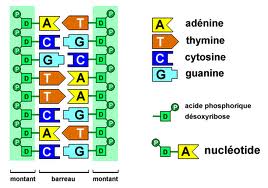
- Cada célula del cuerpo humano (con la excepción de los glóbulos rojos) contiene una secuencia deADN de 3200 millones de letras de longitud, es decir, dos metros de ADN. Y es que un trozo de ADN de un mm de longitud contiene una secuencia de pares de bases de más de tres millones de letras.
- Es como la receta de un guiso o el código de un programa informático. El ADN está formado por largas secuencias de moléculas llamadas bases nitrogenadas que aparecen en cuatro “sabores”: adenina (A), citosina (C), guanina (G) y timina (T). Al descubrirse, se creyó imposible que solo cuatro letras pudieran contener las instrucciones de la inmensa complejidad de un organismo completo: sería como escribir la Enciclopedia Británica con sólo cuatro letras.
- Pero es posible escribir tantas instrucciones con sólo cuatro letras, tal y como explica Joel Levy en 100 analogías científicas:
Las proteínas están compuestas por 20 aminoácidos diferentes, así que lo que se necesita es un código capaz de cifrar al menos 20 mensajes (o codones) diferentes. Como cada letra presenta cuatro opciones, las secuencias de dos bases sólo permitirían 16 (4×4) palabras de dos letras, o codones. Pero si las secuencias tienen tres bases, es posible transmitir 64 (4×4×4) codones distintos, más que suficiente si se quieren especificar 20 aminoácidos.
- Para asimilar la cantidad de letras que componen el genoma humano, debemos imaginarnos tecleando en el ordenador 60 palabras por minuto, ocho horas al día… durante 50 años. Y es que el ADN de una simple ameba unicelular ya contiene hasta 400 millones de bits de información genética, lo suficiente para escribir 80 libros de 500 páginas cada uno.
- El ADN puede preservarse durante mucho tiempo: las muestras más antiguas encontradas hasta el momento corresponden a plantas, mamuts y otros animales siberianos de hace 400 000 años.
- Las sustancias químicas y otros agentes atacan y dañan con frecuencia el ADN de una célula humana a un ritmo, en términos generales, de 10000 veces al día. Alteraciones en un solo gen son las causantes de entre 3000 y 4000 enfermedades hereditarias.
- Si desenrrolláramos todo el ADN de las células de un cuerpo humano, cubriríamos la distancia de la Tierra a la Luna 7000 veces. Veamos los cálculos: el total de células del cuerpo humano (dos billones = 2 × 1012 células) y la longitud equivale al recorrido de 7000 viajes de ida y vuelta a la Luna (distancia Tierra – Luna = 300000 Km)
- Para que os hagáis una idea de la información que contiene, os recomiendo echar un vistazo a ¿Cuánta información tiene almacenada la humanidad?
- Christian Bök, profesor de escritura creativa de la Universidad de Calgary (Canadá) consiguió grabar unos versos poéticos en el ADN de una bacteria. El alfabeto que utiliza es el mismo código genético, gracias al cual se interpreta dicho ADN, que es traducido a las proteínas a las que ha dado lugar.
Fuente: Pagina12
![]()
Falta de rigor científico en el hallazgo de huesos de Ricardo III
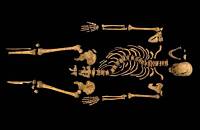
Pese al anuncio a bombo y platillo del hallazgo de los huesos del rey inglés bajo un aparcamiento, la comunidad científica todavía plantea dudas sobre su verdadera identidad.
Tras meses de expectación, la Universidad de Leicester había convocado el lunes a periodistas de todo el mundo. En agosto de 2012, un grupo de científicos había encontrado en las ruinas de un monasterio bajo un aparcamiento de la ciudad inglesa los huesos de un hombre fallecido de manera brutal en el siglo XV. Le habían reventado la cabeza posiblemente con una alabarda. Y los investigadores sospechaban que podía tratarse de Ricardo III, que gobernó Inglaterra entre 1483 y 1485, cuando murió en la batalla de Bosworth defendiendo su trono.
Por fin, el lunes, en una rueda de prensa convertida en un entretenido show, el arqueólogo Richard Buckley proclamó que esos huesos destrozados son, “más allá de toda duda razonable”, lo que queda del monarca Ricardo III, célebre por su frase “Mi reino por un caballo” en la obra de Shakespeare. Los investigadores se abrazaron y los periodistas se levantaron y aplaudieron a rabiar. El hallazgo del rey inglés dio la vuelta al mundo.
Un carpintero canadiense
Para averiguar si los huesos del aparcamiento eran del rey Ricardo III, los investigadores de la Universidad de Leicester compararon su ADN con el de Michael Ibsen, un carpintero de Canadá que se ha identificado como descendiente de la hermana mayor del monarca inglés. El ADN, el microscópico libro de instrucciones en el que está escrito el funcionamiento biológico de un ser humano, se encuentra en el núcleo de cada una de nuestras células, pero fuera de él las mitocondrias, las pilas que suministran energía a las células, tienen su propio ADN. Este ADN mitocondrial se hereda de madres a hijos y se suele utilizar para saber si dos personas están emparentadas. Y, según explicaron los científicos ingleses en la rueda de prensa, el ADN mitocondrial del aparcamiento y el del carpintero coinciden.
“En el hipotético caso de que hayan encontrado un macheo [una coincidencia] entre las dos secuencias de ADN, es posible que estén emparentados, pero que estos sean los restos del rey es otro cantar”, expone Camiña, experto en la genética de las dinastías de los Austrias y de los Borbones. “Queremos que se contrasten los resultados y que expertos en historia comenten el tema”, lanza.
Cuando genetistas de la Universidad de Santiago de Compostela buscaron por curiosidad el estudio científico de los restos humanos del aparcamiento de Leicester, para saber cómo se había averiguado que pertenecían al rey Ricardo III, no lo encontraron. Y no lo encontraron porque no existe. En una estrategia más propia del marketing que de la ciencia, los autores del estudio no han publicado sus análisis en una revista científica para que sus colegas de todo el mundo puedan consultarlos.
Ampliar en: Materia
Bajo licencia Creative Commons
![]()
Recurso contra las huellas de ADN según proyecto ENCODE
¿Es inconstitucional la identificación mediante ADN? Un Tribunal de Apelaciones de EE.UU. podría estar a punto de decidir que lo es, según la ciencia más reciente.
Las huellas genéticas de ADN es una parte rutinaria de la recogida de datos sobre los acusados ??de delitos graves en los EE.UU.. La huella de ADN comprende marcadores – conocidos como marcadores CODIS – que no codifican para proteínas pero ayudan a distinguir los individuos entre sí.
Algunos de a quienes se le tomaron huellas de ADN dicen que el registro de los marcadores CODIS incumple su privacidad, y se ha puesto en marcha un caso de apelación.
Los resultados de la Enciclopedia de Elementos de ADN proyecto (ENCODE) – revelados el mes pasado – pueden desempeñar un importante papel en el caso. The Electronic Frontier Foundation (EFF), un grupo de defensa de derechos digitales, ha ofrecido información sobre ENCODE a la apelación. Se dice que los resultados del proyecto confirman que el ADN sin funcionamiento desempeña un papel en el comportamiento celular.
Muchos investigadores no están de acuerdo con la evaluación de EFF. No es habitual que los marcadores CODIS individuales sirvan para dar cualquier información que viole la privacidad, dice Ryan Gregory de la Universidad de Guelph en Ontario, Canadá.
Sin embargo, existe una clara posibilidad de que los tribunales consideren el escrito de la EFF, según David Kaye de Penn State law school in University Park. «Creo que podría ser un juez, y tal vez más de uno, los que se refieran a ella como muestra de que no podemos estar seguros en que el perfil CODIS tiene valor sólo en el establecimiento de la identidad individual».
Las transcripciones de las audiencias hasta el momento, hacen que sea difícil saber por dónde van los jueces y como se inclinan, dice Kaye, porque los jueces a menudo tienen el papel de abogado del diablo durante el interrogatorio. Sin embargo, los tribunales tienen un historial de citar la ciencia actual en los resultados, por lo que es probable que los resultados ENCODE se discutirán en la decisión.
Afirma Gregory «Las pruebas genéticas ayudan a exonerar a la gente, podría darse un retroceso a causa de una mala interpretación de un estudio».
Fuente: NewScientist
Enlace importante sobre el proyecto ENCODE
![]()
Los transgénicos (OGM) no causan suicidios de agricultores
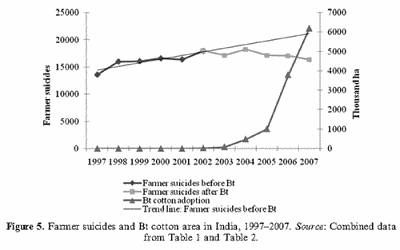
En discusiones sobre los beneficios de los vegetales transgénicos con los opositores fanáticos, es probable que saquen a relucir el tema del incremento de suicidios de granjeros indios, según ellos, debido a la introducción de cultivos transgénicos.
Esta afirmación bien vale la pena ser estudiada, datos en mano, y así lo hicieron un par de investigadores, con unos resultados muy claros, según se visualiza en la gráfica previa.
El algodón Bt es acusado de ser responsable de un aumento de los suicidios de agricultores en la India. En este artículo ofrecemos una revisión exhaustiva de la evidencia sobre el algodón Bt y los suicidios de agricultores. Los datos disponibles no muestran ninguna evidencia de un ‘resurgimiento’ de suicidios de agricultores. Por otra parte, la tecnología de algodón Bt ha sido muy eficaz en general en la India. Sin embargo, en distritos y años específicos, el algodón Bt puede haber contribuido indirectamente al endeudamiento campesino, lo que lleva a suicidios, pero su fracaso fue principalmente el resultado del contexto o entorno en el que fue plantado.
Fuente: DE AVANZADA
![]()
El ADN tiene una vida media de 521 años

Artículo publicado por Matt Kaplan el 10 de octubre de 2012 en Nature News
No puede recuperarse material genético de los dinosaurios, pero dura más de lo que se pensaba.
Pocos investigadores han dado crédito a las afirmaciones de que han sobrevivido muestras de ADN de dinosaurio hasta la actualidad, pero nadie sabía cuánto tiempo tardaba en desmembrarse el material genético. Ahora, un estudio realizado sobre fósiles encontrados en Nueva Zelanda, zanja la cuestión – y acaba con las esperanzas de clonar un Tyrannosaurus rex.
Rendimientos decrecientes
Comparando la edad de los especímenes y los niveles de degradación del ADN, los investigadores calcularon que la vida media del ADN es de 521 años. Esto significa que tras 521 años, se habrían perdido la mitad de los enlaces entre los nucleótidos en la estructura de una muestra; tras otros 521 se perderían la mitad del resto, y así sucesivamente.
El equipo predice que incluso en un hueso a una temperatura de conservación ideal de ?5 ºC, cada enlace se destruiría de manera efectiva tras un máximo de 6,8 millones de años. El ADN dejaría de ser legible mucho antes – tal vez apenas tras 1,5 millones de años, cuando las hebras restantes fuesen demasiado cortas para ofrecer una información con sentido.
“Esto confirma la sospecha general que afirma que el ADN procedente de dinosaurios y antiguos insectos atrapados en ámbar es incorrecta”, dice Simon Ho, biólogo evolutivo computacional de la Universidad de Sídney en Australia. Sin embargo, aunque 6,8 millones de años no es, ni de lejos, la edad de un hueso de dinosaurio – que tendría unos 65 millones de años – “podríamos ser capaces de romper el récord de la secuencia de ADN auténtica más antigua, que actualmente está en medio millón de años”, señala Ho.
Los cálculos del último estudio son bastante sencillos, pero aún quedan muchas preguntas.
“Estoy muy interesado en ver si estos hallazgos pueden reproducirse en entornos muy distintos como el permafrost y las cuevas”, dice Michael Knapp, paleogenetista en la Universidad de Otago en Dunedin, Nueva Zelanda.
Además, los investigadores encontraron que la diferencia de edad tenía en cuenta apenas un 38,6% de la variación en la degradación del ADN entre las muestras de huesos de moas. “Claramente están en marcha otros factores que impactan en la conservación del ADN”, dice Bunce. “El almacenamiento tras la excavación, la química del suelo e incluso la época del año en la que murió el animal son factores que probablemente contribuyen y que habrá que tener en cuenta”.
Artículo completo en: Ciencia Kanija
![]()
Dudas sobre «Proyecto ENCODE y el supuesto fin del ADN basura»
Algunos titulares «discutibles»:
- El «ADN basura» tiene un propósito según revela un nuevo mapa del genoma humano (CBC News)
- El estudio Encode demuele la teoría del «ADN basura» (Wired, The Independent)
- El concepto del «ADN basura» demolido por un nuevo análisis del genoma humano (The Washington Post)
- El ADN basura, demolido (The Wall Street Journal)
- No existe ADN basura (QUO)
- El ADN basura es esencial para el funcionamiento del genoma humano (Expansión)
En realidad está muy bien probada la existencia de grandes cantidades de ADN basura en los genomas de los seres vivos de todo tipo (hasta en las bacterias). Los trabajos recién publicados a los que se hace referencia en esas noticias no han tirado por tierra este «concepto» del ADN basura, ni sus autores lo han afirmado en esos trabajos.
En el blog el Paleo Freak dan respuesta a diversas preguntas sobre este tema de actualidad
¿Qué es el ADN basura?
Aunque no hay una definición perfectamente consensuada, en general se entiende que el ADN basura es aquel que no tiene ninguna función biológica, que existe en el genoma sin aportar características ventajosas o útiles al organismo portador, y cuya acumulación es tolerada hasta cierto punto. Puede incluir, por ejemplo, restos de antiguos genes que se han degradado o restos de secuencias de origen «parasitario» (inserciones de virus, transposones defectivos, etc.).
¿Es lo mismo ADN basura que ADN no codificante?
No. El ADN no codificante es toda secuencia de ADN que no codifica (no sirve para especificar) la secuencia de una proteína. A veces se dice que es el ADN que no consiste en genes (aunque podríamos discutir durante horas la definición de gen). Se sabe desde hace mucho tiempo que el ADN no codificante puede tener diversas funciones, como por ejemplo regular la producción de las proteínas. Es un error llamar «ADN basura» a todo el ADN no codificante, o en general a las secuencias que no conocemos bien. Sin embargo, está bien probado que gran parte del ADN no codificante es realmente ADN basura.
¿No será que el ADN basura tiene una función, pero no la conocemos?
Partiendo de la teoría evolutiva y del conocimiento acumulado hasta ahora sobre genética y genómica, parece muy improbable (por no decir imposible) que todo el ADN tenga una función, porque eso implicaría que existe un mecanismo misterioso que inmediatamente le «encuentra» una utilidad a todas y cada una de las secuencias que se desactivan por mutaciones o que aparecen como consecuencia de transposiciones e infecciones. También es prácticamente imposible que la selección natural elimine cualquier secuencia inútil que aparezca en un genoma, ya que su coste energético y por tanto su influencia en el número de hijos del individuo va a ser despreciable (especialmente en un ser vivo tan enorme como un humano). Solo cuando la acumulación de estas secuencias «se sale de madre» y comienza a suponer una desventaja, la selección natural empezará a «sacar la basura». Estos argumentos teóricos, y otros más largos y difíciles de explicar, hacen inevitable la existencia del ADN sin función en los genomas, especialmente en los genomas grandes. Pero además, experimentalmente se comprueba que hay secuencias que evolucionan como cabría esperar si no tuvieran función y resultaran «invisibles» a la selección natural.
¿Por qué este malentendido es nefasto para la lucha contra el creacionismo?
Porque los creacionistas niegan la existencia del ADN basura ya que, según ellos Dios, ha diseñado los sistemas biológicos, y no es digno de Dios ponerse a crear basura en el genoma. Los creacionistas llevan años publicando artículos tóxicos y desinformativos sobre la investigación del ADN no codificante. Los titulares del principio de este post suponen un triunfo estratégico para ellos.
Ampliar en: Paleo Freak
![]()
Desvergüenza de empresas de cosméticos (ADN)
El ADN es una molécula que sirve para almacenar información genética, pero no para quitar las arrugas. Por lo tanto el efecto de todas estas cremas “mágicas” es el mismo que todas las cremas hidratantes, solo que mucho más caras.
Es conocida la desvergüenza de muchas empresas de cosméticos a la hora de publicitar sus productos. Con alegría y poco rigor suelen mezclar conceptos científicos con otros que no lo son y trufar sus anuncios con un lenguaje pseudocientífico, que puede servir para convencer a un cliente poco informado. Entre ejemplos recientes podemos encontrar la crema basada en células madre de manzana o cuando L’Oréal decidió que la arginina no era un aminoácido porque sonaba mal.
En los años 90 del siglo pasado empezaron a venderse cremas con ARN vegetales como antienvejecimiento. El problema es que el ARN siempre tiene la misma composición química, sea vegetal o de virus. Lo que cambia entre diferentes organismos es el orden de las piezas que lo forman (los ribonucleótidos), es decir, la secuencia. Además es una molécula muy inestable y nuestra piel (para defenderse de los virus) tiene moléculas que degradan ARN, por lo que suponiendo que los ARN vegetales se conserven en la crema, al contacto con la piel se degradaran por lo que dará igual que fueran de pepino, de rata o del virus de la gripe. Por lo demás ¿los ARN (enteros o degradados) tienen algún efecto sobre la piel? No, fuera de su contexto dentro de la célula donde realizan diversas funciones, son moléculas muy aburridas y desde luego, no quitan las arrugas. Esto no quita que varias empresas de cosmética sigan explotando el filón.
El ADN en las células de la piel no entra, pero ¿Tiene algún efecto sobre la epidermis? El ADN no tiene actividad enzimática como antioxidante, ni sirve para regenerar el epitelio, ni tiene capacidad para hidratar, por lo tanto, mal vamos. Siendo muy generoso, el único efecto positivo sería que si te pusieras muchísimo ADN en la piel (la composición no dice que porcentaje de la crema es ADN) podría recibir parte de la radiación UV del sol y si degrada el ADN foráneo no degradará el de la célula, por lo tanto protegería de la radiación de sol, pero esto es una tontería porque cualquier protector solar es mucho más efectivo y más barato que ponerse ADN en la piel. Ives Rocher también está en el negocio, en plan fino, es decir con ADN vegetal, aunque no dicen de que planta. Además según la publicidad engañosa de Ives Rocher el ADN vegetal tiene más propiedades que el anillo de Frodo, protege, revitaliza, regenera, depigmenta, ilumina…
Ampliar en: Amazings.es
![]()
Pasando el testigo de la vida, de Schrödinger a Venter

Hace sesenta y nueve años, Erwin Schrödinger se paró frente a una multitud en el Trinity College de Dublín, Irlanda, y abordó uno de los mayores interrogantes de la ciencia: ¿Qué es la vida? Ayer por la noche, el genetista Craig Venter frente a una multitud reunida en la misma universidad, realizó esa misma pregunta.
Una década después Schrödinger fue galardonado con el Premio Nobel por su trabajo en la teoría atómica, el físico austríaco se desempeñaba como el primer director de la escuela de física teórica en el recién creado Instituto de Estudios Avanzados de Dublín. En una conferencia pública en febrero de 1943, dirigió su atención a la naturaleza física del gen. Poco se sabía acerca de la composición de los genes en esa etapa, pero Schrödinger propuso que un gen puede ser considerado como un «cristal aperiódico».
Que resultó ser una idea clave, dijo Luke O’Neill , profesor de bioquímica en el Trinity College y el maestro de ceremonias en el evento de anoche. «El gen tenían que ser estable, por lo que debería ser un cristal, y tenía que contener la información por lo que era aperiódico», explicó.
«Igualmente importante, Schrödinger también discutió la posibilidad de un código genético, indicando el concepto en términos claros y físicos.»Pero mientras que sus puntos de vista específicos han tenido una influencia tremenda, el hecho de que Schrödinger estaba viendo la biología a través de una lente de físico tuvo un efecto dominó a través de diferentes disciplinas. «Un escrito sobre la biología del famoso físico inspiró a muchos físicos y químicos para examinar las cuestiones biológicas», dijo O’Neill.
La serie de conversaciones de Schrödinger a lo largo de tres viernes y el libro que siguió pasó a tener una influencia importante en la ciencia. Al mirar la vida desde una perspectiva física, Schrödinger inspiró a investigadores como James Watson , quien junto con sus colegas, desarrolló la estructura de doble hélice del ADN en los años 1950 y ganó el premio Nobel en 1962.
¿Cuán apropiado es entonces que Venter subió al podio para ofrecer una actualización del siglo 21 de las conferencias de Schrödinger? Watson se encontraba entre la multitud.
Venter, que ha leído el «librito» de Schrödinger al menos cinco veces, hizo una historia resumida de los descubrimientos sobre el ADN y sus funciones en la célula. Él describió cómo los genomas ahora pueden secuenciarse en un relámpago en comparación relativa con los ‘viejos’ días de tan sólo 10 o 15 años atrás, y habló sobre el trabajo de su equipo en la síntesis de ADN artificial para reiniciar el sistema de células.
«Todas las células vivas que conocemos en este planeta son máquinas biológicas impulsadas por software-ADN, compuestas de cientos de miles de robots de proteínas, codificadas por el ADN, que llevan a cabo las funciones precisas», dijo Venter. «Ahora estamos utilizando un programa informático para el diseño de nuevo software ADN».
Los mundos digitales y biológicos se están convirtiendo en intercambiables, añadió, describiendo cómo los científicos ahora sólo tiene que enviar unos a otros la información para hacer material de bricolaje biológico en lugar de enviar el material en sí.
Venter también delineó una visión de los dispositivos convertidores pequeños que se pueden conectar a los ordenadores para hacer las estructuras a partir de información digital – tal vez el futuro podía vernos distribución de la información para hacer las vacunas, los alimentos y combustibles en todo el mundo, o incluso en otros planetas. «Esta es la biología que se mueve a la velocidad de la luz», dijo.
Pero tal vez la más intrigante anécdota compartida por Venter fue su descripción de cómo su equipo añade marca de agua a su ADN sintetizado, con citas codificadas de James Joyce, Robert Oppenheimer y Richard Feynman, sólo para enterarse que se habían incluido un error en la cita de Feynman.
Por último, en un momento tan esperado, Watson se unió a Venter en el escenario para un estruendoso aplauso. Si sólo Schrödinger podría haber estado allí también.
La conferencia en el Trinity College de Dublín, fue organizado por la Real Academia Irlandesa en el marco de Euroscience Open Forum 2012 , que se extiende hasta el 15 de julio en Dublín.
Fuente: NewScientist
![]()
El humilde ADN podría ayudar a descifrar la materia oscura
Unas hebras de ADN podrían ayudar a resolver el misterio de la materia oscura. Un detector de nueva propuesta tiene como objetivo usar el ADN para resolver los resultados contradictorios de los actuales detectores de materia oscura.
La materia oscura se cree que representan alrededor del 85 por ciento de la materia total en el universo. Los principales sospechosos son las llamadas «partículas masivas de interacción débil (WIMP)», que son inmunes a las fuerzas electromagnéticas y nucleares fuertes. En teoría, las WIMP´s interactuan con la materia normal sólo a través de la gravedad y la fuerza nuclear débil.
Los intentos de detectar WIMP en la Tierra han proporcionado resultados contradictorios. En el ámbito positivo, dos experimentos – Cogent en Soudan, Minnesota (EE.UU.), y DAMA / LIBRA en el Gran Sasso (Italia), han visto partículas oscuras que golpean a sus detectores de materia más supuestos en junio que en diciembre. Todo lo demás es igual, el exceso se atribuye a la velocidad relativa de la Tierra a través del mar de la materia oscura que llena nuestra galaxia. En junio, la Tierra se está moviendo en la misma dirección que el sol y por lo tanto se encuentra con un «viento de frente» de la materia oscura, dice la teoría. En diciembre, la Tierra en su órbita alrededor del sol, se está moviendo en sentido opuesto.
Pero, sobre todo, otros experimentos más grandes y más sensibles, tales como CDMS-II y XENON100, no han visto ninguna de tales partículas. Una forma de resolver el conflicto sería detectar la direccionalidad de partículas de materia oscura, para ver si efectivamente están alineados con la dirección del movimiento del sol a través de la galaxia, como lo requiere DAMA / LIBRA.
Ahora Andrzej Drukier de Biotraces – una empresa de biotecnología con sede en Herndon, Virginia – y un grupo de cosmólogos y bioquímicos sugieren que el ADN podría ayudar a romper el callejón sin salida.
Su detector propuesto consta de una hoja de un metro cuadrado de lámina de oro y un «bosque» de una sola capa en suspensión por debajo de moléculas de ADN en un conjunto ordenado, al igual que las cerdas de un cepillo de dientes. Cuando un WIMP golpea un átomo de oro en el papel de aluminio, sería desalojar un núcleo de oro y enviar su impulso a través de la matriz, con la ruptura de las cadenas de ADN a lo largo de su trayectoria. Las partículas energéticas como los rayos cósmicos se ha demostrado que chocan y se rompen con hebras de ADN, aunque WIMPs tienen una energía mucho menor.
Las cadenas de ADN rotas se reunierán, posteriormente amplificadas y analizadas para determinar exactamente donde se rompió cada cadena. Dado que la secuencia de bases que forman cada hebra de ADN es bien sabida, la ubicación del corte en cada hebra – y por lo tanto la trayectoria del núcleo de oro – podrían ser rastreados en el rango de un nanómetro en tres dimensiones, alrededor de 1000 veces mejor resolución que los detectores actuales.
«La resolución más alta significa que tendríamos más datos de eventos WIMP», afirma el miembro del equipo George Church, de la Universidad de Harvard.
Dicha resolución 3D permitiría a los cosmólogos inferir tanto la energía y la dirección de un WIMP, que a su vez podría confirmar la existencia de la predicción de viento «WIMP» creado por el movimiento del sistema solar a través de la galaxia.
Un detector basado en ADN también tiene otras ventajas, afirma. Se puede operar a temperatura ambiente, en oposición a cerca del cero absoluto para detectores de corriente. Y al cambiar el material de la lámina, se puede ajustar para buscar partículas de diferentes energías, incluidas las WIMPs al parecer detectadas por Cogent y DAMA / LIBRA. El equipo ahora está probando la viabilidad del diseño.
El miembro del equipo COGENT Juan Collar de la Universidad de Chicago, quien no está involucrado con la propuesta, dice que un detector de WIMP basado en el ADN es intrigante. «La detección direccional de la materia oscura es el santo grial en nuestro campo», afirma.
Fuente: arXiv:1206.6809v1
![]()
Científicos descodifican el ADN de un bebé no nacido
Investigadores de la Universidad de Washington (EE.UU.) han secuenciado el genoma completo de un feto. El avance científico podría ayudar a detectar ciertas enfermedades en el útero, pero algunos expertos temen que el tesoro de la información genética puede ser más aterrador y abrumador que útil.
Disuelto en la sangre de una mujer embarazada – junto con alguna información adicional a partir de la saliva- se esconde suficiente ADN del feto para trazar el mapa genético completo de un bebé no nacido.
Puede sonar como algo evocado por Julio Verne, pero que pasó en la Universidad de Washington: un profesor y un estudiante graduado utilizaron muestras de ADN de los padres de un bebé que todavía estaba en el útero y reconstruyeron su estructura genética, desde la A a la Z .
El relato, publicado el miércoles en Science Translational Medicine, indica que se realizaron pruebas prenatales a nuevos niveles, prometiendo información genética de un niño que ni siquiera se había imaginado – junto con un tesoro de datos correspondientes que incluso los expertos aún no saben cómo interpretar.
Jacob Kitzman, autora principal y un estudiante graduado en el departamento de ciencias del genoma en la Universidad de Washington (UW), estaban emocionados pero cautelosos sobre los logros de su equipo. «Ha habido un montón de pasos hacia esto, pero esta es la primera vez que se captura todo el genoma», dice Kitzman. «El hecho de que esta tecnología ya está en camino de convertirse en clínicamente viable es una buena oportunidad para una discusión más amplia de las consecuencias.»
Averiguar cómo comunicar la gran cantidad de información descubierta por la secuenciación del genoma sigue siendo controvertido, ya que gran parte de ella todavía no es clínicamente útil. Sin embargo, aunque los investigadores no entienden el significado de la totalidad de la información revelada a través de secuenciación del genoma completo, lo que sí sabemos es que ciertos genes son responsables de trastornos mendelianos, o más simples, los trastornos de un único gen – que incluyen más de 3000 enfermedades como la la fibrosis quística, enfermedad de Tay-Sachs y algunas distrofias musculares que afectan al 1% de los embarazos. La secuenciación prenatal permite a los padres saber antes del nacimiento si su niño tiene alguna de estas enfermedades, muchas de las cuales son debilitantes o mortales. Si bien la detección genética de los padres antes del embarazo también puede identificar a los portadores, y un número creciente de pruebas prenatalesbasadas en ADN se pueden determinar al comienzo del embarazo si los bebés en desarrollo tienen condiciones específicas, tales como el síndrome de Down, toda la secuenciación del genoma es la forma más sofisticada para examinar una persona mediante su código genético entero.
Fuente: TIME Healthland
![]()
Las huellas dactilares de ADN entran en el siglo 21

Para crear un perfil de ADN de una víctima o perpetrador de una actividad delictiva, la Oficina Federal de Investigaciones (FBI) de EE.UU. analiza en una muestra de ADN por lo menos 13 repeticiones en tándem cortas (STRs). STRs son las colecciones repetidas de dos a seis secuencias de nucleótidos, como CTGCTGCTG, que se encuentran dispersas en todo el genoma. Debido a que el número de repeticiones en los RTS puede mutar rápidamente, en cada persona el conjunto de estos marcadores genéticos es diferente de todos los de otra persona, hacer informes sobre transacciones sospechosas es ideal para crear una huella digital única de ADN.
El FBI presentó su primer sistema de identificación de STR en 1998, cuando ROS eran las preferidas de la comunidad genética. Sin embargo, otros marcadores de identificación genéticos se descubrieron pronto y ganaron popularidad. Por la misma época, un alto rendimiento de secuenciación permitió a los investigadores procesar grandes cantidades de ADN, pero utilizando métodos que eran ineficaces en el ADN repetido, incluyendo informes sobre transacciones sospechosas. Los informes sobre transacciones sospechosas fueron olvidados en su mayoría por los genetistas, y las innovaciones para su estudio se estancó.
Los investigadores del Instituto Whitehead han retirado STR de identificación en el siglo 21 mediante la creación de lobSTR, un sistema de tres pasos que precisa a la vez perfiles de más de 100 000 informes sobre transacciones sospechosas de una secuencia del genoma humano en un día, una hazaña que los sistemas anteriores nunca pudieron completar. El algoritmo lobSTR se describe en la edición de mayo de la revista Genome Research.
«LobSTR encontró que en un genoma humano, el 55% de los informes sobre transacciones sospechosas son polimórficos, que mostraron algunas diferencias, lo cual es muy sorprendente», dice Whitehead compañero de Yaniv Erlich. «Por lo general, la tasa de polimorfismo de ADN es muy bajo porque la mayor parte del ADN es idéntico entre dos personas. Con esta herramienta, que proporciona acceso a decenas de miles de marcadores rápidamente cambiantes que no se podía conseguir antes, y los que se puede utilizar en la genética médica, la población la genética y la medicina forense «.
Para crear una huella de ADN, lobSTR primero escanea todo un genoma para identificar todos los informes sobre transacciones sospechosas y qué patrón de nucleótidos se repite en los tramos de ADN. A continuación, toma nota de las secuencias lobSTR no repetidsa que flanquean los extremos de los RTS. Estas secuencias fijan la ubicación de cada STR, en el genoma y determinan el número de repeticiones en los informes sobre transacciones sospechosas. Por último, lobSTR elimina el «ruido» para producir una descripción exacta de la configuración de los informes sobre transacciones sospechosas.
De acuerdo con Melissa Gymrek, que es el autor principal del artículo de Genome Research, la capacidad de lobSTR para describir con precisión y eficiencia miles de informes sobre transacciones sospechosas en un genoma ha abierto muchas nuevas oportunidades de investigación.
«El siguiente primer paso y simple es la caracterización de la cantidad de variación STR en los individuos y las poblaciones», dice Gymrek, que era un investigador universitario en el laboratorio de Erlich cuando trabajaba en lobSTR. «Esto proporcionará el conocimiento de la gama normal de alelos STR en cada lugar, que serán de utilidad en estudios de genética médica que les gustaría para determinar si un determinado alelo es normal o que puedan ser patógenos. Otra dirección que estamos viendo es mirar en los RTS en los estudios de caso/control en busca de informes sobre transacciones sospechosas asociadas con la enfermedad. La lista es interminable, pero estas son algunas de las primeras preguntas que estamos buscando para hacer frente «.
Fuente: Whitehead Institute for Biomedical Research (2012, April 27). DNA fingerprinting enters 21st century. ScienceDaily. Retrieved April 28, 2012, http://www.sciencedaily.com/releases/2012/04/120427163418.htm
![]()

